 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELSA: Enhanced Local Self-Attention for Vision Transformer
Paper and Code
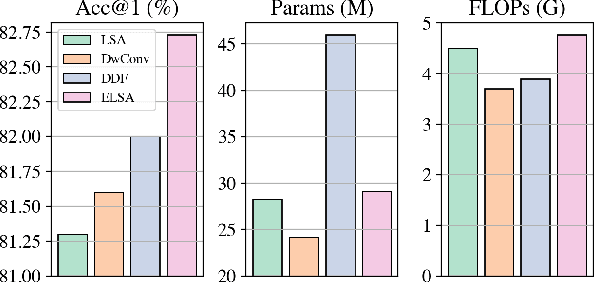

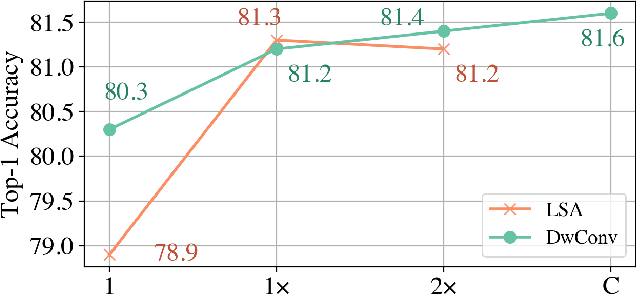

Self-attention is powerful in modeling long-range dependencies, but it is weak in local finer-level feature learning. The performance of local self-attention (LSA) is just on par with convolution and inferior to dynamic filters, which puzzles researchers on whether to use LSA or its counterparts, which one is better, and what makes LSA mediocre. To clarify these, we comprehensively investigate LSA and its counterparts from two sides: \emph{channel setting} and \emph{spatial processing}. We find that the devil lies in the generation and application of spatial attention, where relative position embeddings and the neighboring filter application are key factors. Based on these findings, we propose the enhanced local self-attention (ELSA) with Hadamard attention and the ghost head. Hadamard attention introduces the Hadamard product to efficiently generate attention in the neighboring case, while maintaining the high-order mapping. The ghost head combines attention maps with static matrices to increase channel capacity. Experiments demonstrate the effectiveness of ELSA. Without architecture / hyperparameter modification, drop-in replacing LSA with ELSA boosts Swin Transformer \cite{swin} by up to +1.4 on top-1 accuracy. ELSA also consistently benefits VOLO \cite{volo} from D1 to D5, where ELSA-VOLO-D5 achieves 87.2 on the ImageNet-1K without extra training images. In addition, we evaluate ELSA in downstream tasks. ELSA significantly improves the baseline by up to +1.9 box Ap / +1.3 mask Ap on the COCO, and by up to +1.9 mIoU on the ADE20K. Code is available at \url{https://github.com/damo-cv/ELSA}.