 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Neural Networks for Classification
Paper and Code
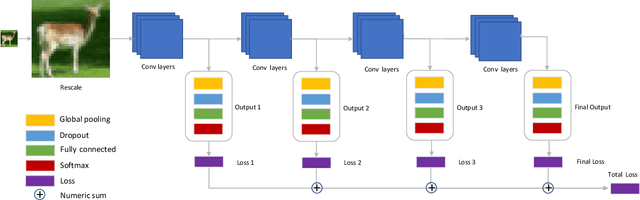
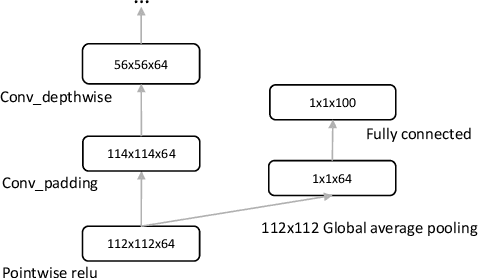
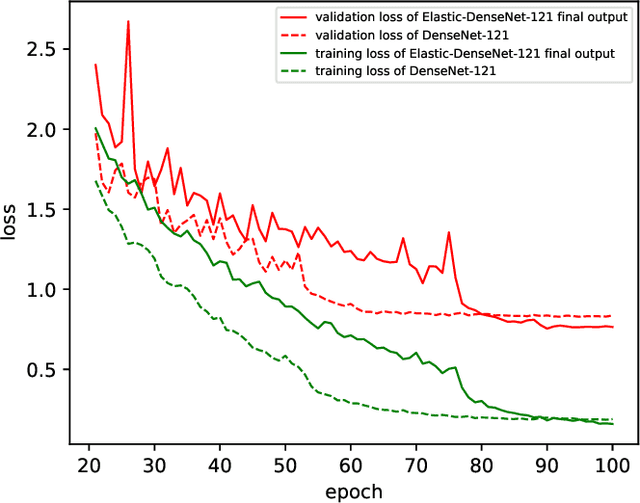
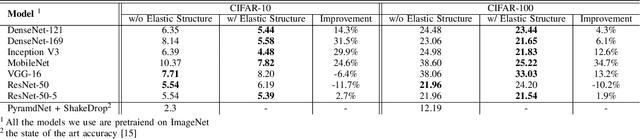
In this work we propose a framework for improving the performance of any deep neural network that may suffer from vanishing gradients. To address the vanishing gradient issue, we study a framework, where we insert an intermediate output branch after each layer in the computational graph and use the corresponding prediction loss for feeding the gradient to the early layers. The framework - which we name Elastic network - is tested with several well-known networks on CIFAR10 and CIFAR100 datasets, and the experimental results show that the proposed framework improves the accuracy on both shallow networks (e.g., MobileNet) and deep convolutional neural networks (e.g., DenseNet). We also identify the types of networks where the framework does not improve the performance and discuss the reasons. Finally, as a side product, the computational complexity of the resulting networks can be adjusted in an elastic manner by selecting the output branch according to current computational budget.