Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenvalues of the Hessian in Deep Learning: Singularity and Beyond
Paper and Code
Oct 05, 2017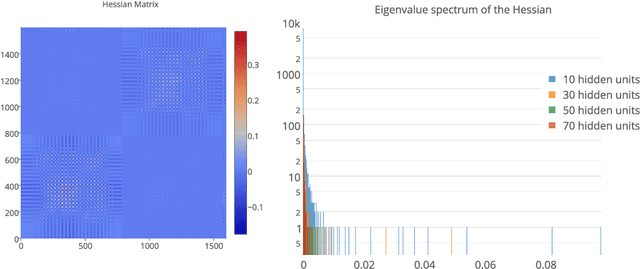
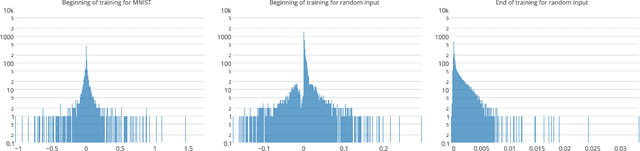
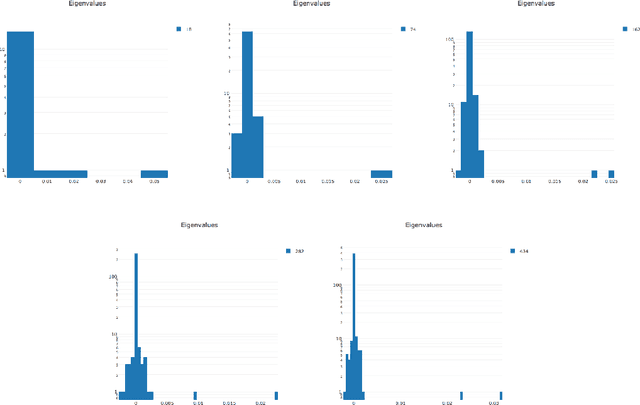
We look at the eigenvalues of the Hessian of a loss function before and after training. The eigenvalue distribution is seen to be composed of two parts, the bulk which is concentrated around zero, and the edges which are scattered away from zero. We present empirical evidence for the bulk indicating how over-parametrized the system is, and for the edges that depend on the input data.
* ICLR submission, 2016 - updated to match the openreview.net version
View paper on
 OpenReview
OpenReview