 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-Downward and Ambient Video based Person Location Association
Paper and Code
Dec 02, 2018
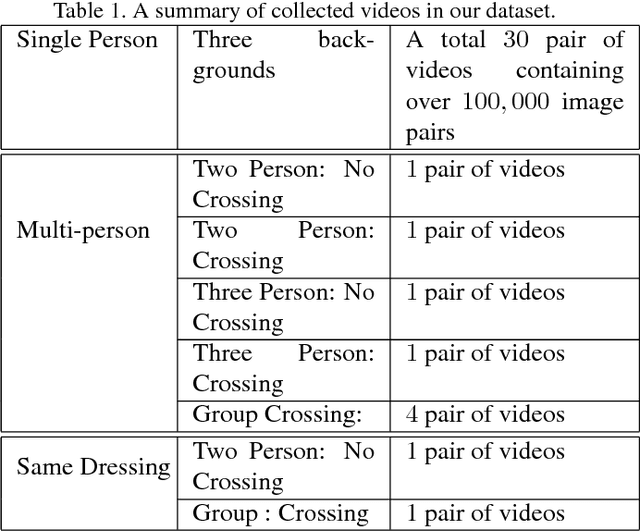
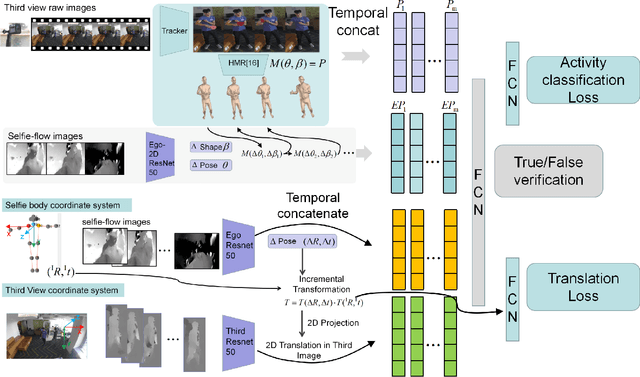
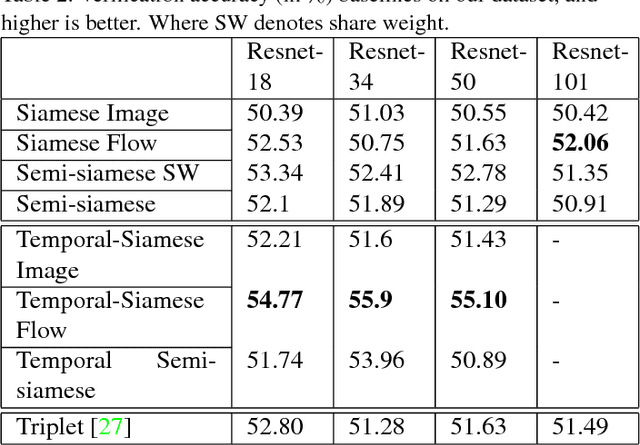
Using an ego-centric camera to do localization and tracking is highly needed for urban navigation and indoor assistive system when GPS is not available or not accurate enough. The traditional hand-designed feature tracking and estimation approach would fail without visible features. Recently, there are several works exploring to use context features to do localization. However, all of these suffer severe accuracy loss if given no visual context information. To provide a possible solution to this problem, this paper proposes a camera system with both ego-downward and third-static view to perform localization and tracking in a learning approach. Besides, we also proposed a novel action and motion verification model for cross-view verification and localization. We performed comparative experiments based on our collected dataset which considers the same dressing, gender, and background diversity. Results indicate that the proposed model can achieve $18.32 \%$ improvement in accuracy performance. Eventually, we tested the model on multi-people scenarios and obtained an average $67.767 \%$ accuracy.