 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Traffic State Forecasting using Spatio-Temporal Network Dependencies: A Sparse Graph Neural Network Approach
Paper and Code
Nov 06, 2022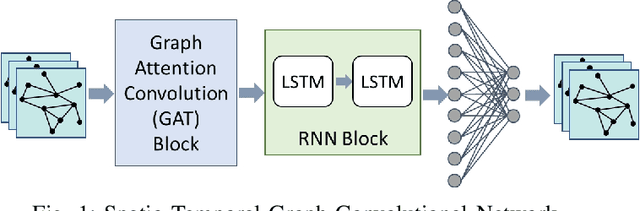
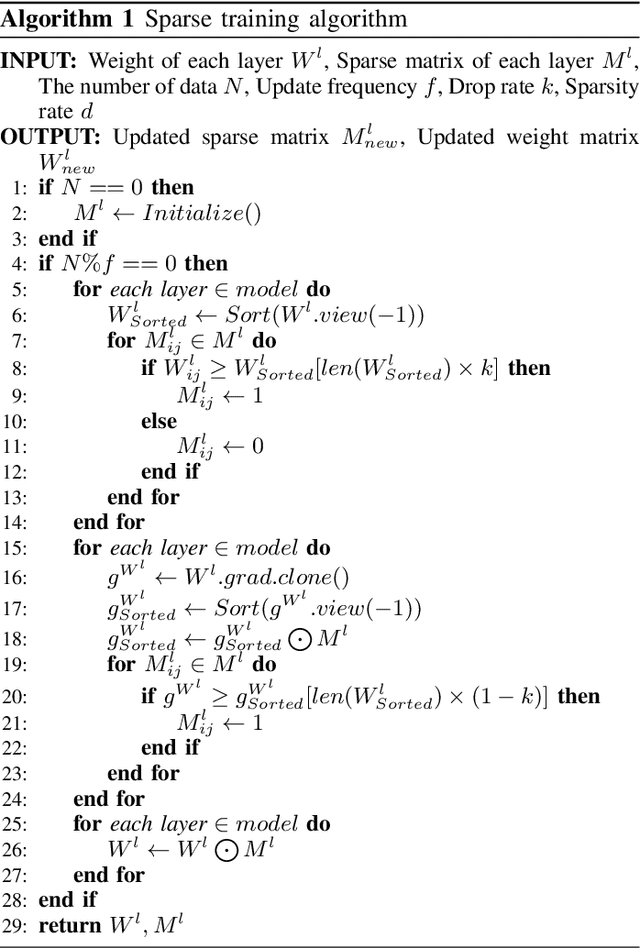
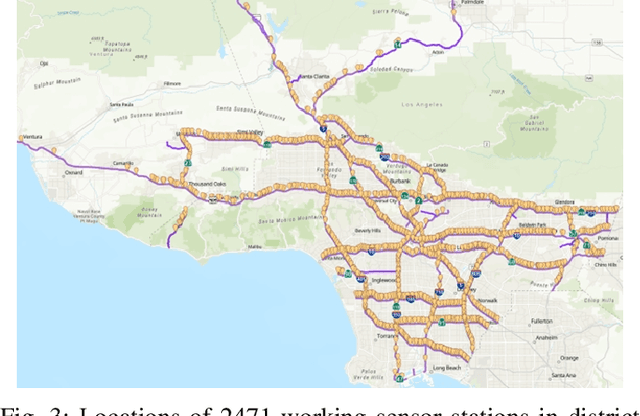
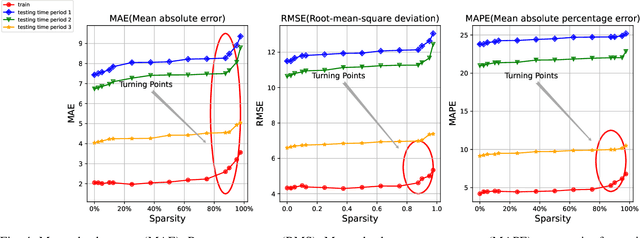
Traffic state prediction in a transportation network is paramount for effective traffic operations and management, as well as informed user and system-level decision-making. However, long-term traffic prediction (beyond 30 minutes into the future) remains challenging in current research. In this work, we integrate the spatio-temporal dependencies in the transportation network from network modeling, together with the graph convolutional network (GCN) and graph attention network (GAT). To further tackle the dramatic computation and memory cost caused by the giant model size (i.e., number of weights) caused by multiple cascaded layers, we propose sparse training to mitigate the training cost, while preserving the prediction accuracy. It is a process of training using a fixed number of nonzero weights in each layer in each iteration. We consider the problem of long-term traffic speed forecasting for a real large-scale transportation network data from the California Department of Transportation (Caltrans) Performance Measurement System (PeMS). Experimental results show that the proposed GCN-STGT and GAT-STGT models achieve low prediction errors on short-, mid- and long-term prediction horizons, of 15, 30 and 45 minutes in duration, respectively. Using our sparse training, we could train from scratch with high sparsity (e.g., up to 90%), equivalent to 10 times floating point operations per second (FLOPs) reduction on computational cost using the same epochs as dense training, and arrive at a model with very small accuracy loss compared with the original dense training