 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Spoken Language Recognition via Multilabel Classification
Paper and Code



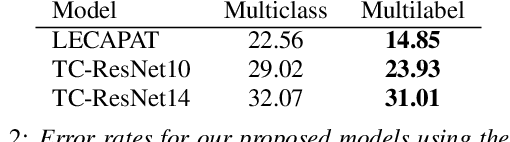
Spoken language recognition (SLR) is the task of automatically identifying the language present in a speech signal. Existing SLR models are either too computationally expensive or too large to run effectively on devices with limited resources. For real-world deployment, a model should also gracefully handle unseen languages outside of the target language set, yet prior work has focused on closed-set classification where all input languages are known a-priori. In this paper we address these two limitations: we explore efficient model architectures for SLR based on convolutional networks, and propose a multilabel training strategy to handle non-target languages at inference time. Using the VoxLingua107 dataset, we show that our models obtain competitive results while being orders of magnitude smaller and faster than current state-of-the-art methods, and that our multilabel strategy is more robust to unseen non-target languages compared to multiclass classification.