 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sparse Subspace Clustering by Nearest Neighbour Filtering
Paper and Code
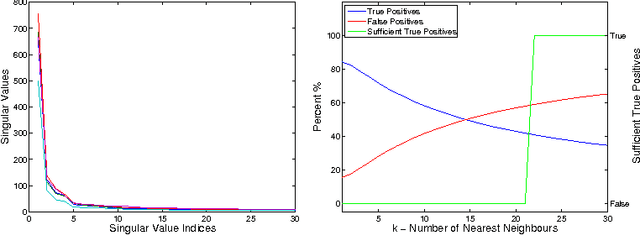



Sparse Subspace Clustering (SSC) has been used extensively for subspace identification tasks due to its theoretical guarantees and relative ease of implementation. However SSC has quadratic computation and memory requirements with respect to the number of input data points. This burden has prohibited SSCs use for all but the smallest datasets. To overcome this we propose a new method, k-SSC, that screens out a large number of data points to both reduce SSC to linear memory and computational requirements. We provide theoretical analysis for the bounds of success for k-SSC. Our experiments show that k-SSC exceeds theoretical expectations and outperforms existing SSC approximations by maintaining the classification performance of SSC. Furthermore in the spirit of reproducible research we have publicly released the source code for k-SSC