 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient softmax approximation for GPUs
Paper and Code
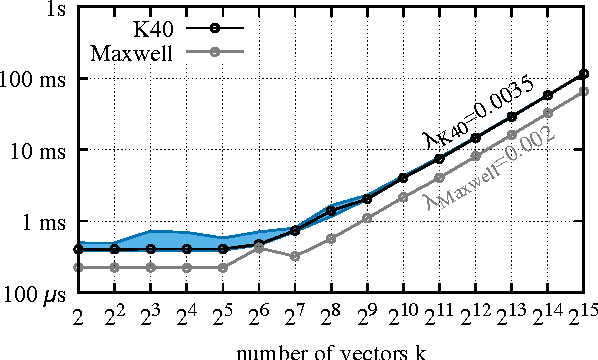
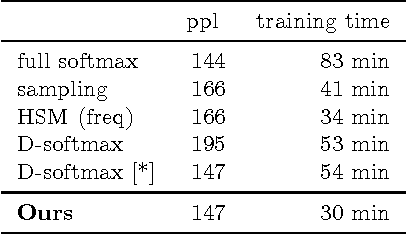

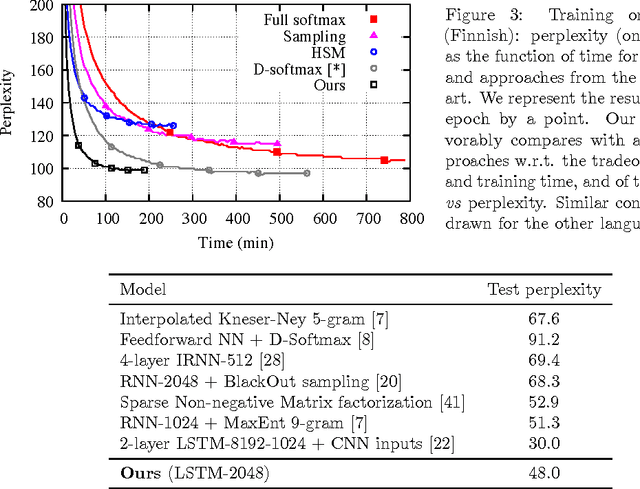
We propose an approximate strategy to efficiently train neural network based language models over very large vocabularies. Our approach, called adaptive softmax, circumvents the linear dependency on the vocabulary size by exploiting the unbalanced word distribution to form clusters that explicitly minimize the expectation of computation time. Our approach further reduces the computational time by exploiting the specificities of modern architectures and matrix-matrix vector operations, making it particularly suited for graphical processing units. Our experiments carried out on standard benchmarks, such as EuroParl and One Billion Word, show that our approach brings a large gain in efficiency over standard approximations while achieving an accuracy close to that of the full softmax. The code of our method is available at https://github.com/facebookresearch/adaptive-softmax.