 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Semiring-Weighted Earley Parsing
Paper and Code

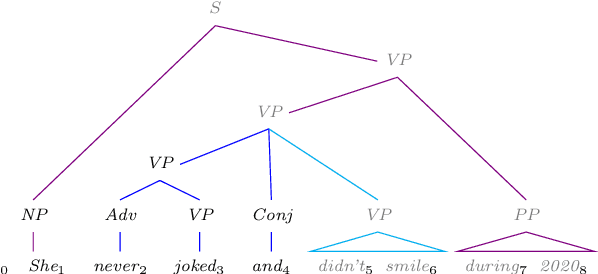
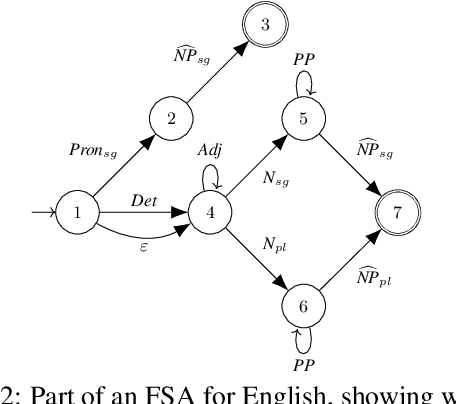

This paper provides a reference description, in the form of a deduction system, of Earley's (1970) context-free parsing algorithm with various speed-ups. Our presentation includes a known worst-case runtime improvement from Earley's $O (N^3|G||R|)$, which is unworkable for the large grammars that arise in natural language processing, to $O (N^3|G|)$, which matches the runtime of CKY on a binarized version of the grammar $G$. Here $N$ is the length of the sentence, $|R|$ is the number of productions in $G$, and $|G|$ is the total length of those productions. We also provide a version that achieves runtime of $O (N^3|M|)$ with $|M| \leq |G|$ when the grammar is represented compactly as a single finite-state automaton $M$ (this is partly novel). We carefully treat the generalization to semiring-weighted deduction, preprocessing the grammar like Stolcke (1995) to eliminate deduction cycles, and further generalize Stolcke's method to compute the weights of sentence prefixes. We also provide implementation details for efficient execution, ensuring that on a preprocessed grammar, the semiring-weighted versions of our methods have the same asymptotic runtime and space requirements as the unweighted methods, including sub-cubic runtime on some grammars.