 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Probabilistic Inference with Partial Ranking Queries
Paper and Code
Feb 14, 2012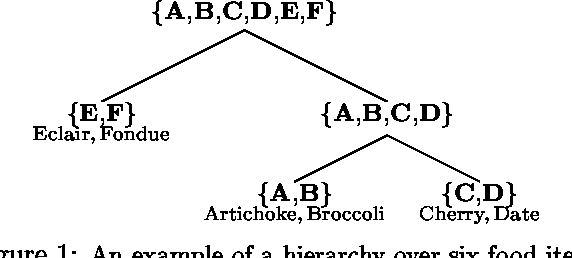
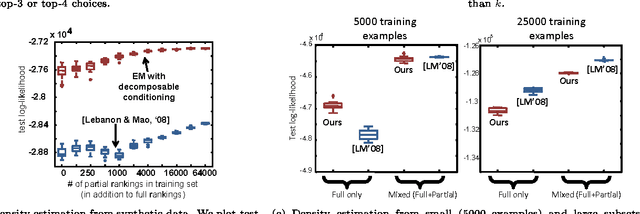
Distributions over rankings are used to model data in various settings such as preference analysis and political elections. The factorial size of the space of rankings, however, typically forces one to make structural assumptions, such as smoothness, sparsity, or probabilistic independence about these underlying distributions. We approach the modeling problem from the computational principle that one should make structural assumptions which allow for efficient calculation of typical probabilistic queries. For ranking models, "typical" queries predominantly take the form of partial ranking queries (e.g., given a user's top-k favorite movies, what are his preferences over remaining movies?). In this paper, we argue that riffled independence factorizations proposed in recent literature [7, 8] are a natural structural assumption for ranking distributions, allowing for particularly efficient processing of partial ranking queries.