 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient non-greedy optimization of decision trees
Paper and Code
Nov 12, 2015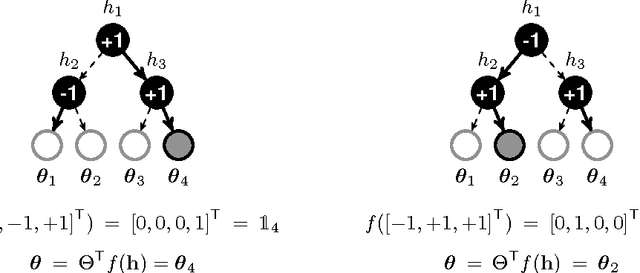
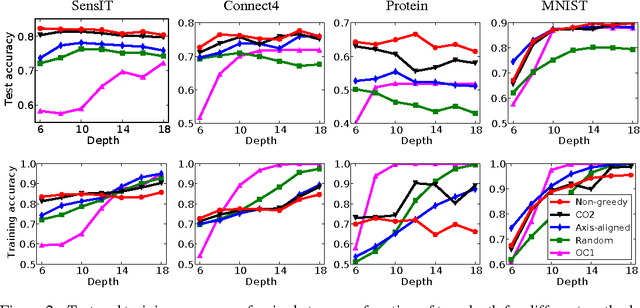
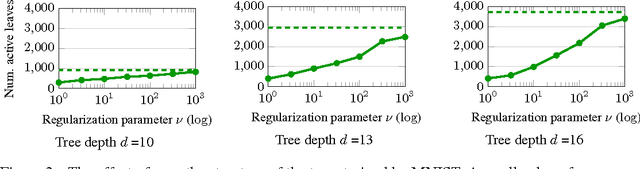
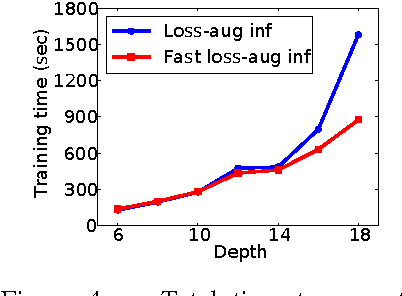
Decision trees and randomized forests are widely used in computer vision and machine learning. Standard algorithms for decision tree induction optimize the split functions one node at a time according to some splitting criteria. This greedy procedure often leads to suboptimal trees. In this paper, we present an algorithm for optimizing the split functions at all levels of the tree jointly with the leaf parameters, based on a global objective. We show that the problem of finding optimal linear-combination (oblique) splits for decision trees is related to structured prediction with latent variables, and we formulate a convex-concave upper bound on the tree's empirical loss. The run-time of computing the gradient of the proposed surrogate objective with respect to each training exemplar is quadratic in the the tree depth, and thus training deep trees is feasible. The use of stochastic gradient descent for optimization enables effective training with large datasets. Experiments on several classification benchmarks demonstrate that the resulting non-greedy decision trees outperform greedy decision tree baselines.