 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Learning of the Parameters of Non-Linear Models using Differentiable Resampling in Particle Filters
Paper and Code
Nov 02, 2021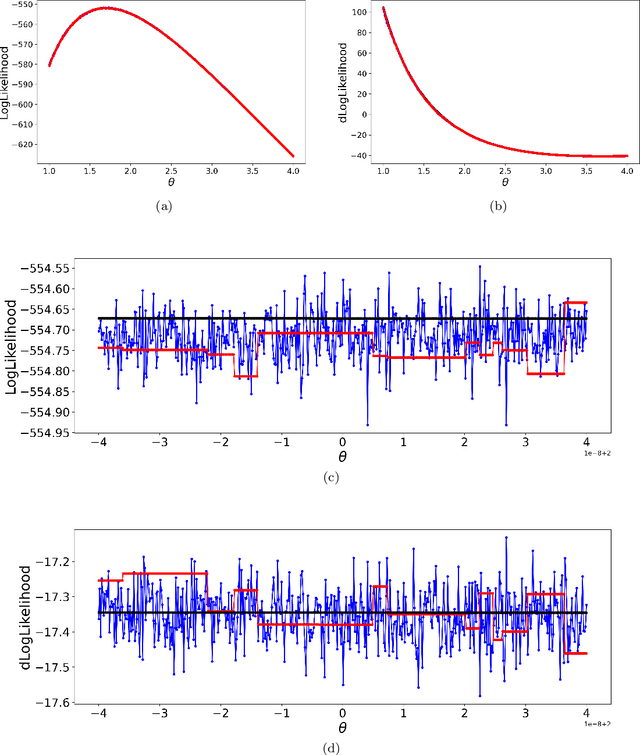



It has been widely documented that the sampling and resampling steps in particle filters cannot be differentiated. The {\itshape reparameterisation trick} was introduced to allow the sampling step to be reformulated into a differentiable function. We extend the {\itshape reparameterisation trick} to include the stochastic input to resampling therefore limiting the discontinuities in the gradient calculation after this step. Knowing the gradients of the prior and likelihood allows us to run particle Markov Chain Monte Carlo (p-MCMC) and use the No-U-Turn Sampler (NUTS) as the proposal when estimating parameters. We compare the Metropolis-adjusted Langevin algorithm (MALA), Hamiltonian Monte Carlo with different number of steps and NUTS. We consider two state-space models and show that NUTS improves the mixing of the Markov chain and can produce more accurate results in less computational time.