 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Forecasting of Large Scale Hierarchical Time Series via Multilevel Clustering
Paper and Code

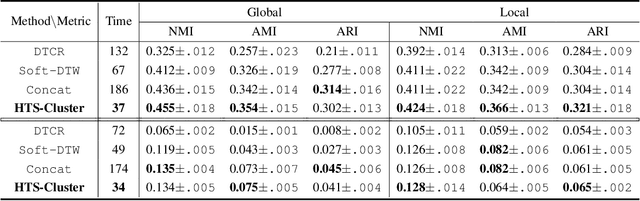


We propose a novel approach to the problem of clustering hierarchically aggregated time-series data, which has remained an understudied problem though it has several commercial applications. We first group time series at each aggregated level, while simultaneously leveraging local and global information. The proposed method can cluster hierarchical time series (HTS) with different lengths and structures. For common two-level hierarchies, we employ a combined objective for local and global clustering over spaces of discrete probability measures, using Wasserstein distance coupled with Soft-DTW divergence. For multi-level hierarchies, we present a bottom-up procedure that progressively leverages lower-level information for higher-level clustering. Our final goal is to improve both the accuracy and speed of forecasts for a larger number of HTS needed for a real-world application. To attain this goal, each time series is first assigned the forecast for its cluster representative, which can be considered as a "shrinkage prior" for the set of time series it represents. Then this base forecast can be quickly fine-tuned to adjust to the specifics of that time series. We empirically show that our method substantially improves performance in terms of both speed and accuracy for large-scale forecasting tasks involving much HTS.