 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Distributed Auto-Differentiation
Paper and Code
Feb 22, 2021
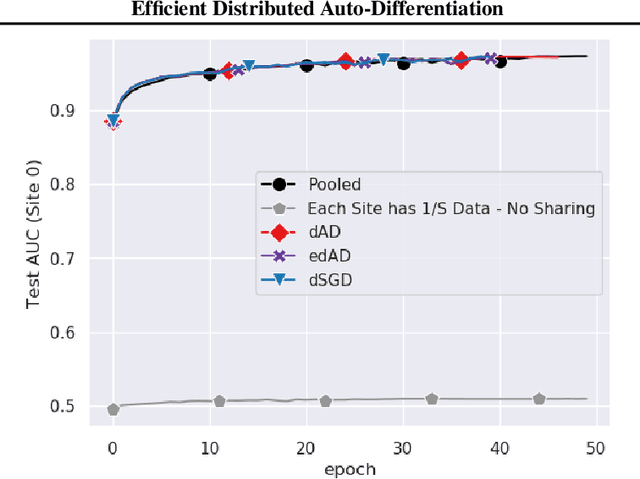


Although distributed machine learning has opened up numerous frontiers of research, the separation of large models across different devices, nodes, and sites can invite significant communication overhead, making reliable training difficult. The focus on gradients as the primary shared statistic during training has led to a number of intuitive algorithms for distributed deep learning; however, gradient-based algorithms for training large deep neural networks (DNNs) are communication-heavy, often requiring additional modifications via sparsity constraints, compression, quantization, and other similar approaches, to lower bandwidth. We introduce a surprisingly simple statistic for training distributed DNNs that is more communication-friendly than the gradient. The error backpropagation process can be modified to share these smaller intermediate values instead of the gradient, reducing communication overhead with no impact on accuracy. The process provides the flexibility of averaging gradients during backpropagation, enabling novel flexible training schemas while leaving room for further bandwidth reduction via existing gradient compression methods. Finally, consideration of the matrices used to compute the gradient inspires a new approach to compression via structured power iterations, which can not only reduce bandwidth but also enable introspection into distributed training dynamics, without significant performance loss.