 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient AutoML Pipeline Search with Matrix and Tensor Factorization
Paper and Code
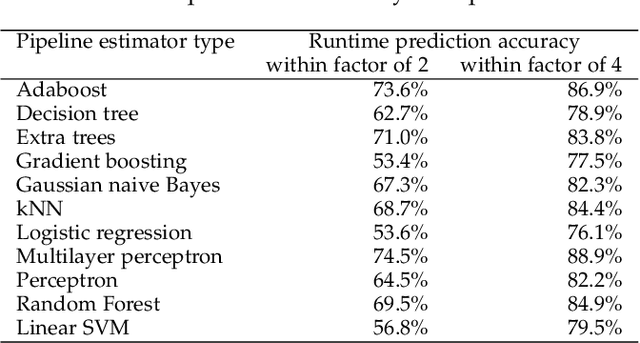
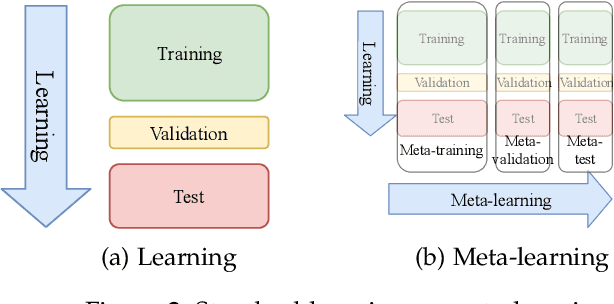

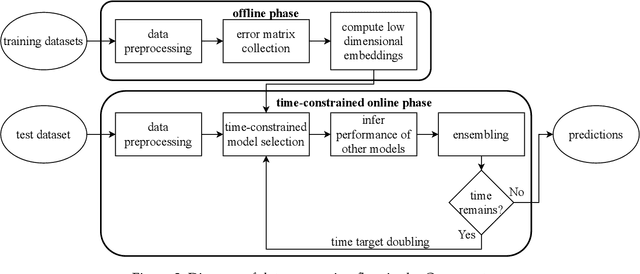
Data scientists seeking a good supervised learning model on a new dataset have many choices to make: they must preprocess the data, select features, possibly reduce the dimension, select an estimation algorithm, and choose hyperparameters for each of these pipeline components. With new pipeline components comes a combinatorial explosion in the number of choices! In this work, we design a new AutoML system to address this challenge: an automated system to design a supervised learning pipeline. Our system uses matrix and tensor factorization as surrogate models to model the combinatorial pipeline search space. Under these models, we develop greedy experiment design protocols to efficiently gather information about a new dataset. Experiments on large corpora of real-world classification problems demonstrate the effectiveness of our approach.