 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Analysis of COVID-19 Clinical Data using Machine Learning Models
Paper and Code
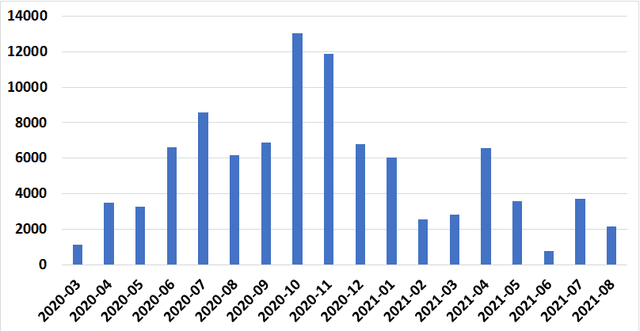

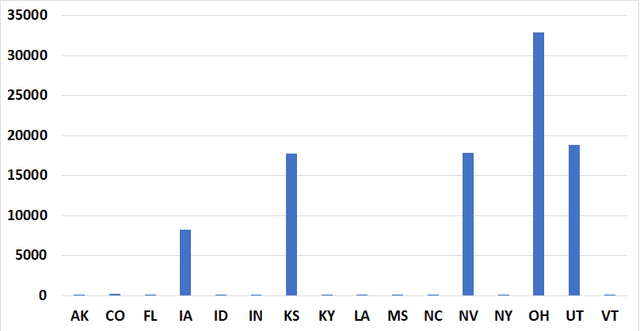

Because of the rapid spread of COVID-19 to almost every part of the globe, huge volumes of data and case studies have been made available, providing researchers with a unique opportunity to find trends and make discoveries like never before, by leveraging such big data. This data is of many different varieties, and can be of different levels of veracity e.g., precise, imprecise, uncertain, and missing, making it challenging to extract important information from such data. Yet, efficient analyses of this continuously growing and evolving COVID-19 data is crucial to inform -- often in real-time -- the relevant measures needed for controlling, mitigating, and ultimately avoiding viral spread. Applying machine learning based algorithms to this big data is a natural approach to take to this aim, since they can quickly scale to such data, and extract the relevant information in the presence of variety and different levels of veracity. This is important for COVID-19, and for potential future pandemics in general. In this paper, we design a straightforward encoding of clinical data (on categorical attributes) into a fixed-length feature vector representation, and then propose a model that first performs efficient feature selection from such representation. We apply this approach on two clinical datasets of the COVID-19 patients and then apply different machine learning algorithms downstream for classification purposes. We show that with the efficient feature selection algorithm, we can achieve a prediction accuracy of more than 90\% in most cases. We also computed the importance of different attributes in the dataset using information gain. This can help the policy makers to focus on only certain attributes for the purposes of studying this disease rather than focusing on multiple random factors that may not be very informative to patient outcomes.