 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Mini-batch SGD for Elastic Distributed Training: Learning in the Limbo of Resources
Paper and Code

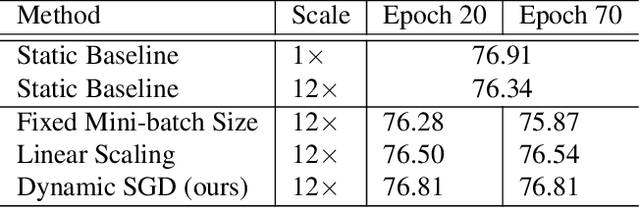


With an increasing demand for training powers for deep learning algorithms and the rapid growth of computation resources in data centers, it is desirable to dynamically schedule different distributed deep learning tasks to maximize resource utilization and reduce cost. In this process, different tasks may receive varying numbers of machines at different time, a setting we call elastic distributed training. Despite the recent successes in large mini-batch distributed training, these methods are rarely tested in elastic distributed training environments and suffer degraded performance in our experiments, when we adjust the learning rate linearly immediately with respect to the batch size. One difficulty we observe is that the noise in the stochastic momentum estimation is accumulated over time and will have delayed effects when the batch size changes. We therefore propose to smoothly adjust the learning rate over time to alleviate the influence of the noisy momentum estimation. Our experiments on image classification, object detection and semantic segmentation have demonstrated that our proposed Dynamic SGD method achieves stabilized performance when varying the number of GPUs from 8 to 128. We also provide theoretical understanding on the optimality of linear learning rate scheduling and the effects of stochastic momentum.