 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Distribution Pruning for Efficient Network Architecture Search
Paper and Code
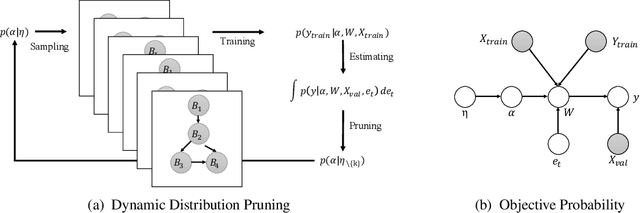
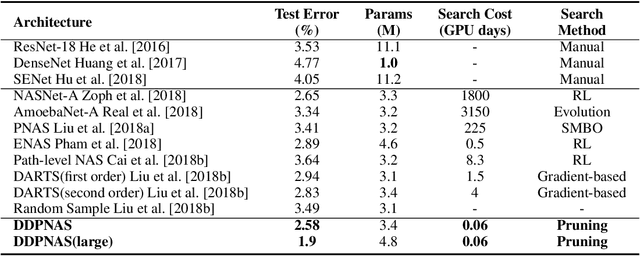
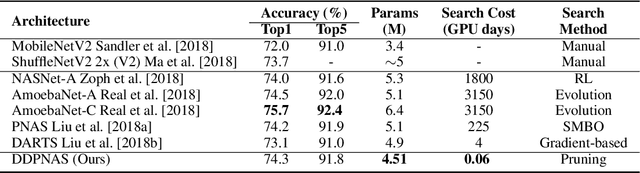
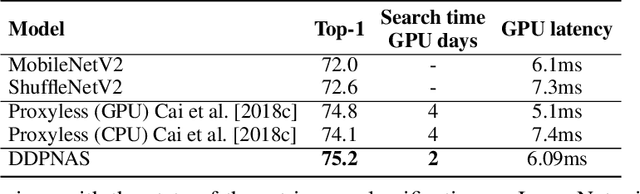
Network architectures obtained by Neural Architecture Search (NAS) have shown state-of-the-art performance in various computer vision tasks. Despite the exciting progress, the computational complexity of the forward-backward propagation and the search process makes it difficult to apply NAS in practice. In particular, most previous methods require thousands of GPU days for the search process to converge. In this paper, we propose a dynamic distribution pruning method towards extremely efficient NAS, which samples architectures from a joint categorical distribution. The search space is dynamically pruned every a few epochs to update this distribution, and the optimal neural architecture is obtained when there is only one structure remained. We conduct experiments on two widely-used datasets in NAS. On CIFAR-10, the optimal structure obtained by our method achieves the state-of-the-art $1.9$\% test error, while the search process is more than $1,000$ times faster (only $1.5$ GPU hours on a Tesla V100) than the state-of-the-art NAS algorithms. On ImageNet, our model achieves 75.2\% top-1 accuracy under the MobileNet settings, with a time cost of only $2$ GPU days that is $100\%$ acceleration over the fastest NAS algorithm. The code is available at \url{ https://github.com/tanglang96/DDPNAS}