 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Preference Distribution Learning for Item Recommendation
Paper and Code
Jan 24, 2022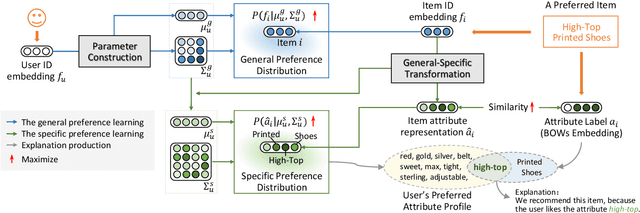
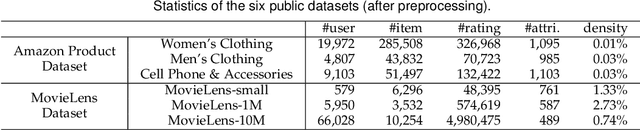
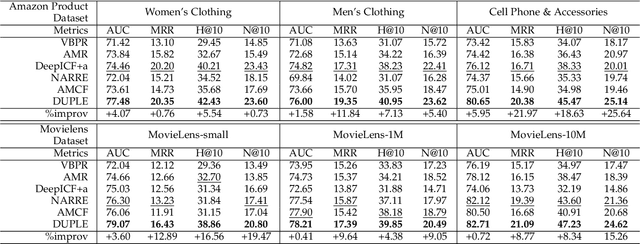
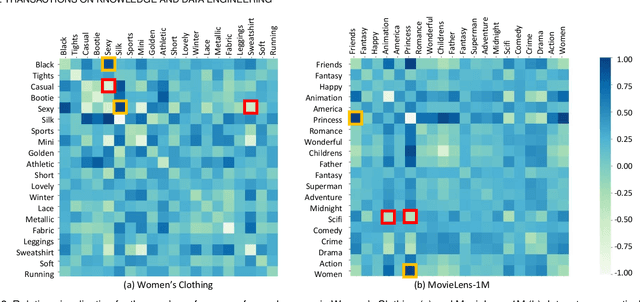
Recommender systems can automatically recommend users items that they probably like, for which the goal is to represent the user and item as well as model their interaction. Existing methods have primarily learned the user's preferences and item's features with vectorized representations, and modeled the user-item interaction by the similarity of their representations. In fact, the user's different preferences are related and capturing such relations could better understand the user's preferences for a better recommendation. Toward this end, we propose to represent the user's preference with multi-variant Gaussian distribution, and model the user-item interaction by calculating the probability density at the item in the user's preference distribution. In this manner, the mean vector of the Gaussian distribution is able to capture the center of the user's preferences, while its covariance matrix captures the relations of these preferences. In particular, in this work, we propose a dual preference distribution learning framework (DUPLE), which captures the user's preferences to both the items and attributes by a Gaussian distribution, respectively. As a byproduct, identifying the user's preference to specific attributes enables us to provide the explanation of recommending an item to the user. Extensive quantitative and qualitative experiments on six public datasets show that DUPLE achieves the best performance over all state-of-the-art recommendation methods.