 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS-TOD: Efficient Domain Specialization for Task Oriented Dialog
Paper and Code
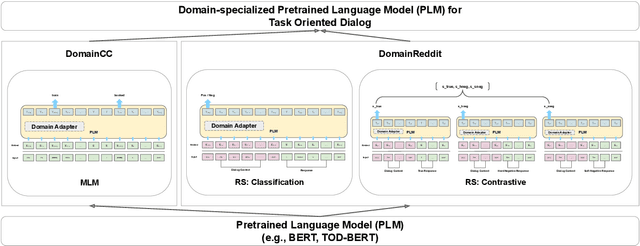



Recent work has shown that self-supervised dialog-specific pretraining on large conversational datasets yields substantial gains over traditional language modeling (LM) pretraining in downstream task-oriented dialog (TOD). These approaches, however, exploit general dialogic corpora (e.g., Reddit) and thus presumably fail to reliably embed domain-specific knowledge useful for concrete downstream TOD domains. In this work, we investigate the effects of domain specialization of pretrained language models (PLMs) for task-oriented dialog. Within our DS-TOD framework, we first automatically extract salient domain-specific terms, and then use them to construct DomainCC and DomainReddit -- resources that we leverage for domain-specific pretraining, based on (i) masked language modeling (MLM) and (ii) response selection (RS) objectives, respectively. We further propose a resource-efficient and modular domain specialization by means of domain adapters -- additional parameter-light layers in which we encode the domain knowledge. Our experiments with two prominent TOD tasks -- dialog state tracking (DST) and response retrieval (RR) -- encompassing five domains from the MultiWOZ TOD benchmark demonstrate the effectiveness of our domain specialization approach. Moreover, we show that the light-weight adapter-based specialization (1) performs comparably to full fine-tuning in single-domain setups and (2) is particularly suitable for multi-domain specialization, in which, besides advantageous computational footprint, it can offer better downstream performance.