 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS-MLR: Exploiting Double Separability for Scaling up Distributed Multinomial Logistic Regression
Paper and Code
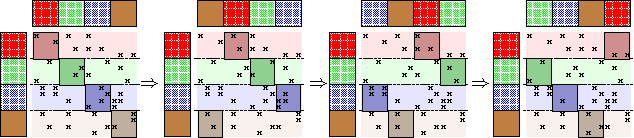
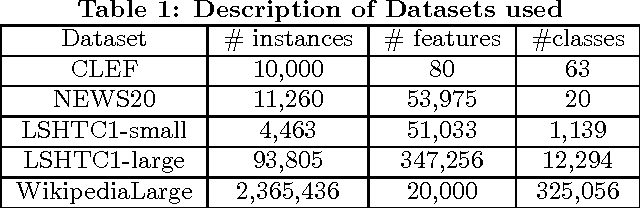
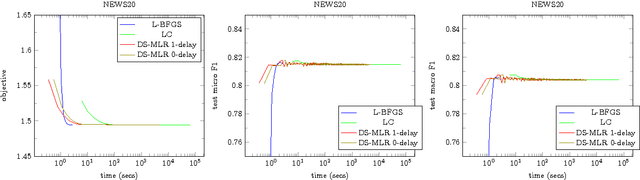
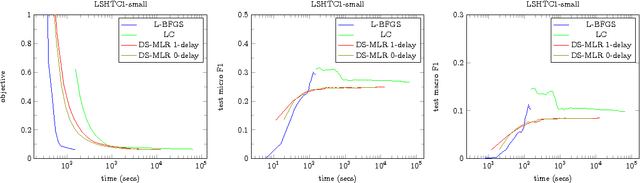
Scaling multinomial logistic regression to datasets with very large number of data points and classes is challenging. This is primarily because one needs to compute the log-partition function on every data point. This makes distributing the computation hard. In this paper, we present a distributed stochastic gradient descent based optimization method (DS-MLR) for scaling up multinomial logistic regression problems to massive scale datasets without hitting any storage constraints on the data and model parameters. Our algorithm exploits double-separability, an attractive property that allows us to achieve both data as well as model parallelism simultaneously. In addition, we introduce a non-blocking and asynchronous variant of our algorithm that avoids bulk-synchronization. We demonstrate the versatility of DS-MLR to various scenarios in data and model parallelism, through an extensive empirical study using several real-world datasets. In particular, we demonstrate the scalability of DS-MLR by solving an extreme multi-class classification problem on the Reddit dataset (159 GB data, 358 GB parameters) where, to the best of our knowledge, no other existing methods apply.