 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamTime: An Improved Optimization Strategy for Text-to-3D Content Creation
Paper and Code
Jun 21, 2023

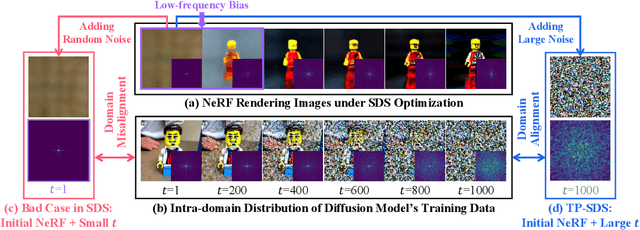

Text-to-image diffusion models pre-trained on billions of image-text pairs have recently enabled text-to-3D content creation by optimizing a randomly initialized Neural Radiance Fields (NeRF) with score distillation. However, the resultant 3D models exhibit two limitations: (a) quality concerns such as saturated color and the Janus problem; (b) extremely low diversity comparing to text-guided image synthesis. In this paper, we show that the conflict between NeRF optimization process and uniform timestep sampling in score distillation is the main reason for these limitations. To resolve this conflict, we propose to prioritize timestep sampling with monotonically non-increasing functions, which aligns NeRF optimization with the sampling process of diffusion model. Extensive experiments show that our simple redesign significantly improves text-to-3D content creation with higher quality and diversity.