 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDraw Your Art Dream: Diverse Digital Art Synthesis with Multimodal Guided Diffusion
Paper and Code


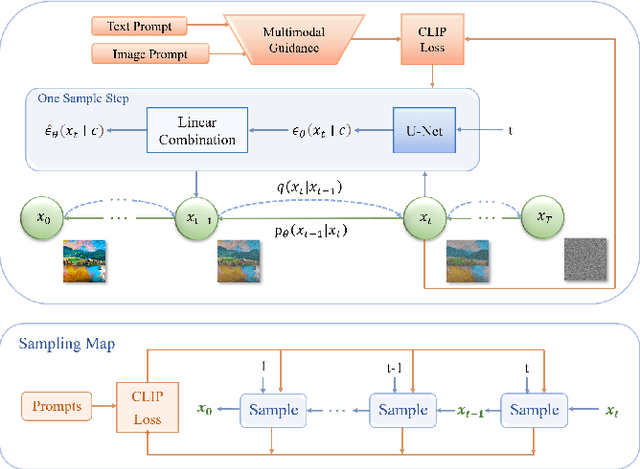

Digital art synthesis is receiving increasing attention in the multimedia community because of engaging the public with art effectively. Current digital art synthesis methods usually use single-modality inputs as guidance, thereby limiting the expressiveness of the model and the diversity of generated results. To solve this problem, we propose the multimodal guided artwork diffusion (MGAD) model, which is a diffusion-based digital artwork generation approach that utilizes multimodal prompts as guidance to control the classifier-free diffusion model. Additionally, the contrastive language-image pretraining (CLIP) model is used to unify text and image modalities. Extensive experimental results on the quality and quantity of the generated digital art paintings confirm the effectiveness of the combination of the diffusion model and multimodal guidance. Code is available at https://github.com/haha-lisa/MGAD-multimodal-guided-artwork-diffusion.