 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble-descent curves in neural networks: a new perspective using Gaussian processes
Paper and Code
Feb 16, 2021
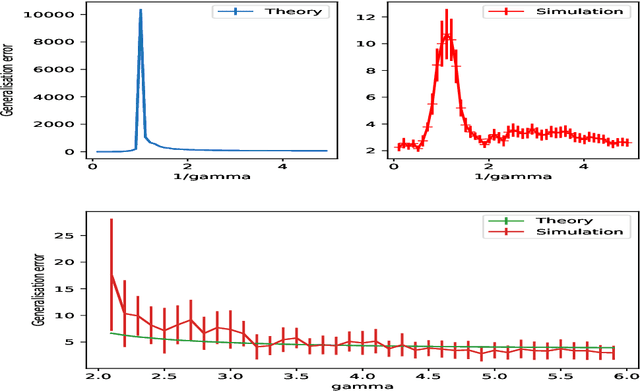
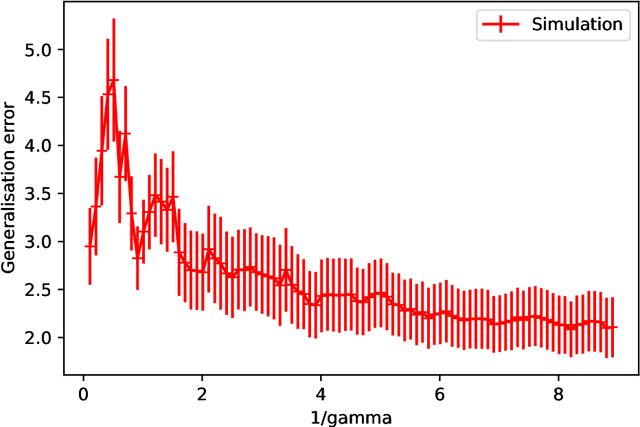
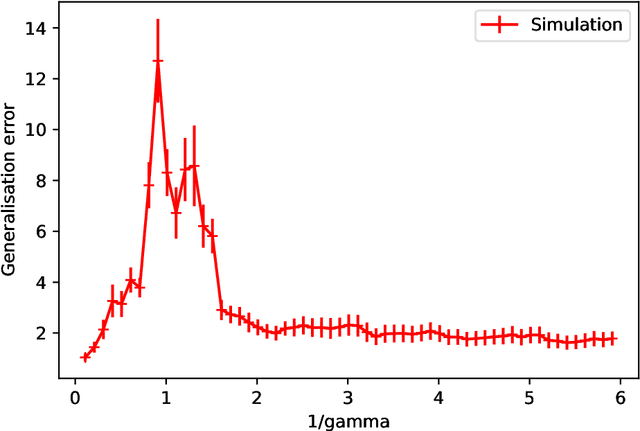
Double-descent curves in neural networks describe the phenomenon that the generalisation error initially descends with increasing parameters, then grows after reaching an optimal number of parameters which is less than the number of data points, but then descends again in the overparameterised regime. Here we use a neural network Gaussian process (NNGP) which maps exactly to a fully connected network (FCN) in the infinite width limit, combined with techniques from random matrix theory, to calculate this generalisation behaviour, with a particular focus on the overparameterised regime. We verify our predictions with numerical simulations of the corresponding Gaussian process regressions. An advantage of our NNGP approach is that the analytical calculations are easier to interpret. We argue that neural network generalization performance improves in the overparameterised regime precisely because that is where they converge to their equivalent Gaussian process.