 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoT: An efficient Double Transformer for NLP tasks with tables
Paper and Code
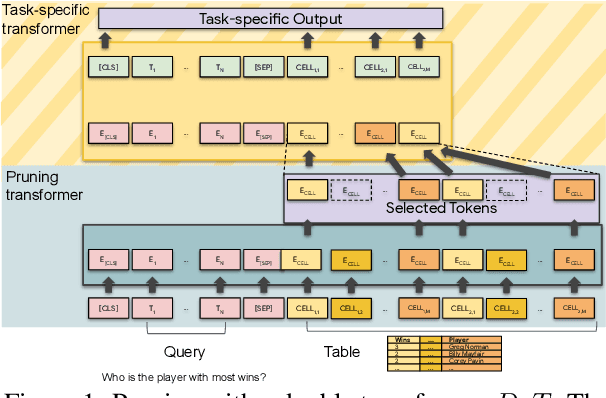
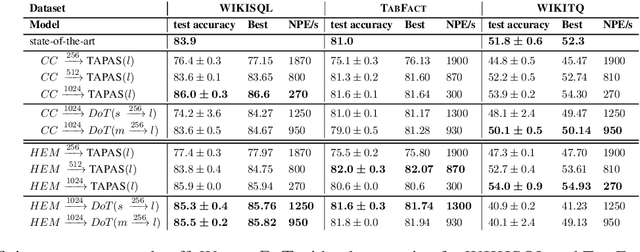
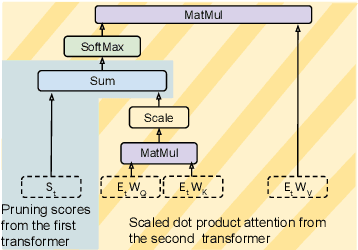
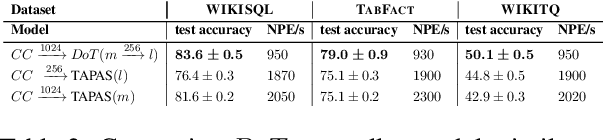
Transformer-based approaches have been successfully used to obtain state-of-the-art accuracy on natural language processing (NLP) tasks with semi-structured tables. These model architectures are typically deep, resulting in slow training and inference, especially for long inputs. To improve efficiency while maintaining a high accuracy, we propose a new architecture, DoT, a double transformer model, that decomposes the problem into two sub-tasks: A shallow pruning transformer that selects the top-K tokens, followed by a deep task-specific transformer that takes as input those K tokens. Additionally, we modify the task-specific attention to incorporate the pruning scores. The two transformers are jointly trained by optimizing the task-specific loss. We run experiments on three benchmarks, including entailment and question-answering. We show that for a small drop of accuracy, DoT improves training and inference time by at least 50%. We also show that the pruning transformer effectively selects relevant tokens enabling the end-to-end model to maintain similar accuracy as slower baseline models. Finally, we analyse the pruning and give some insight into its impact on the task model.