 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Influence in MRI Medical Image Segmentation: spatial versus k-space inputs
Paper and Code
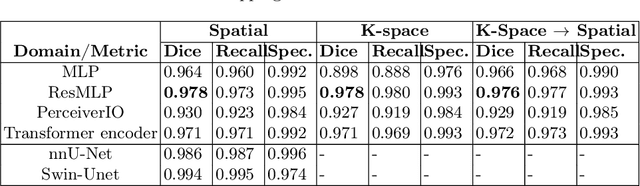



Transformer-based networks applied to image patches have achieved cutting-edge performance in many vision tasks. However, lacking the built-in bias of convolutional neural networks (CNN) for local image statistics, they require large datasets and modifications to capture relationships between patches, especially in segmentation tasks. Images in the frequency domain might be more suitable for the attention mechanism, as local features are represented globally. By transforming images into the frequency domain, local features are represented globally. Due to MRI data acquisition properties, these images are particularly suitable. This work investigates how the image domain (spatial or k-space) affects segmentation results of deep learning (DL) models, focusing on attention-based networks and other non-convolutional models based on MLPs. We also examine the necessity of additional positional encoding for Transformer-based networks when input images are in the frequency domain. For evaluation, we pose a skull stripping task and a brain tissue segmentation task. The attention-based models used are PerceiverIO and a vanilla Transformer encoder. To compare with non-attention-based models, an MLP and ResMLP are also trained and tested. Results are compared with the Swin-Unet, the state-of-the-art medical image segmentation model. Experimental results show that using k-space for the input domain can significantly improve segmentation results. Also, additional positional encoding does not seem beneficial for attention-based networks if the input is in the frequency domain. Although none of the models matched the Swin-Unet's performance, the less complex models showed promising improvements with a different domain choice.