 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Alignment Meets Fully Test-Time Adaptation
Paper and Code
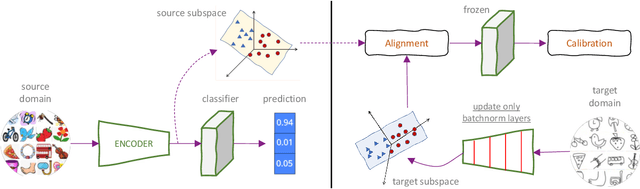

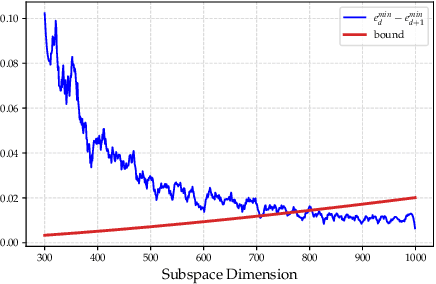
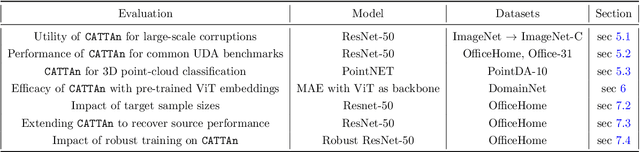
A foundational requirement of a deployed ML model is to generalize to data drawn from a testing distribution that is different from training. A popular solution to this problem is to adapt a pre-trained model to novel domains using only unlabeled data. In this paper, we focus on a challenging variant of this problem, where access to the original source data is restricted. While fully test-time adaptation (FTTA) and unsupervised domain adaptation (UDA) are closely related, the advances in UDA are not readily applicable to TTA, since most UDA methods require access to the source data. Hence, we propose a new approach, CATTAn, that bridges UDA and FTTA, by relaxing the need to access entire source data, through a novel deep subspace alignment strategy. With a minimal overhead of storing the subspace basis set for the source data, CATTAn enables unsupervised alignment between source and target data during adaptation. Through extensive experimental evaluation on multiple 2D and 3D vision benchmarks (ImageNet-C, Office-31, OfficeHome, DomainNet, PointDA-10) and model architectures, we demonstrate significant gains in FTTA performance. Furthermore, we make a number of crucial findings on the utility of the alignment objective even with inherently robust models, pre-trained ViT representations and under low sample availability in the target domain.