 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes SLOPE outperform bridge regression?
Paper and Code
Oct 04, 2019

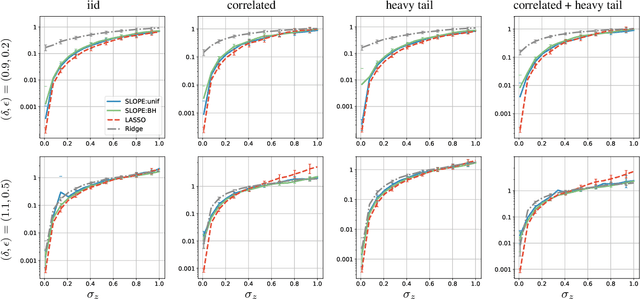
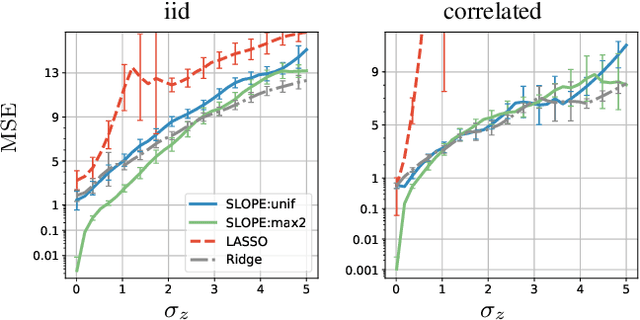
A recently proposed SLOPE estimator (arXiv:1407.3824) has been shown to adaptively achieve the minimax $\ell_2$ estimation rate under high-dimensional sparse linear regression models (arXiv:1503.08393). Such minimax optimality holds in the regime where the sparsity level $k$, sample size $n$, and dimension $p$ satisfy $k/p \rightarrow 0$, $k\log p/n \rightarrow 0$. In this paper, we characterize the estimation error of SLOPE under the complementary regime where both $k$ and $n$ scale linearly with $p$, and provide new insights into the performance of SLOPE estimators. We first derive a concentration inequality for the finite sample mean square error (MSE) of SLOPE. The quantity that MSE concentrates around takes a complicated and implicit form. With delicate analysis of the quantity, we prove that among all SLOPE estimators, LASSO is optimal for estimating $k$-sparse parameter vectors that do not have tied non-zero components in the low noise scenario. On the other hand, in the large noise scenario, the family of SLOPE estimators are sub-optimal compared with bridge regression such as the Ridge estimator.