 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo language models learn typicality judgments from text?
Paper and Code
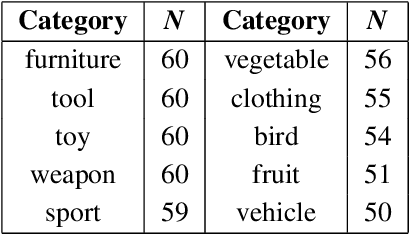
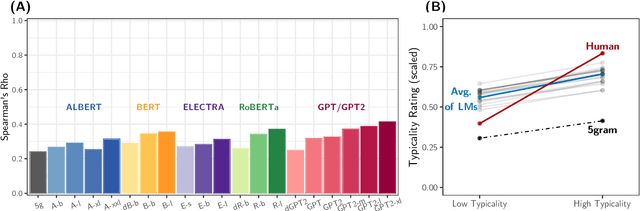

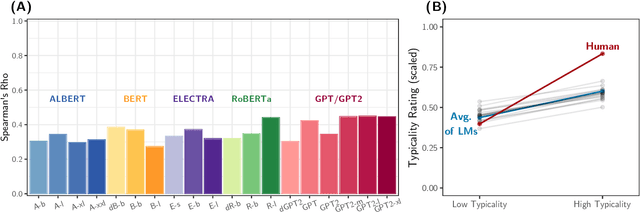
Building on research arguing for the possibility of conceptual and categorical knowledge acquisition through statistics contained in language, we evaluate predictive language models (LMs) -- informed solely by textual input -- on a prevalent phenomenon in cognitive science: typicality. Inspired by experiments that involve language processing and show robust typicality effects in humans, we propose two tests for LMs. Our first test targets whether typicality modulates LM probabilities in assigning taxonomic category memberships to items. The second test investigates sensitivities to typicality in LMs' probabilities when extending new information about items to their categories. Both tests show modest -- but not completely absent -- correspondence between LMs and humans, suggesting that text-based exposure alone is insufficient to acquire typicality knowledge.