 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivided Attention: Unsupervised Multi-Object Discovery with Contextually Separated Slots
Paper and Code
Apr 04, 2023
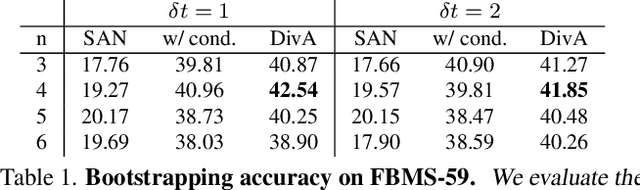
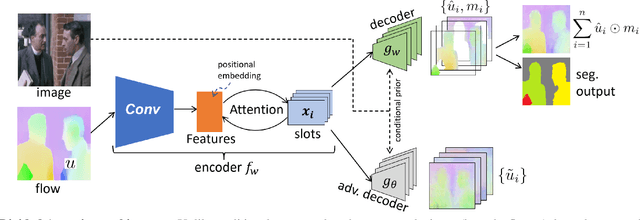
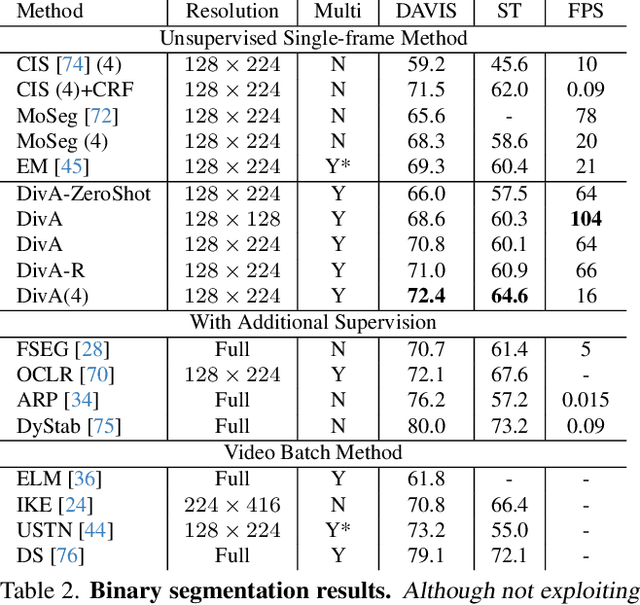
We introduce a method to segment the visual field into independently moving regions, trained with no ground truth or supervision. It consists of an adversarial conditional encoder-decoder architecture based on Slot Attention, modified to use the image as context to decode optical flow without attempting to reconstruct the image itself. In the resulting multi-modal representation, one modality (flow) feeds the encoder to produce separate latent codes (slots), whereas the other modality (image) conditions the decoder to generate the first (flow) from the slots. This design frees the representation from having to encode complex nuisance variability in the image due to, for instance, illumination and reflectance properties of the scene. Since customary autoencoding based on minimizing the reconstruction error does not preclude the entire flow from being encoded into a single slot, we modify the loss to an adversarial criterion based on Contextual Information Separation. The resulting min-max optimization fosters the separation of objects and their assignment to different attention slots, leading to Divided Attention, or DivA. DivA outperforms recent unsupervised multi-object motion segmentation methods while tripling run-time speed up to 104FPS and reducing the performance gap from supervised methods to 12% or less. DivA can handle different numbers of objects and different image sizes at training and test time, is invariant to permutation of object labels, and does not require explicit regularization.