 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Submodular Maximization
Paper and Code
Jun 06, 2018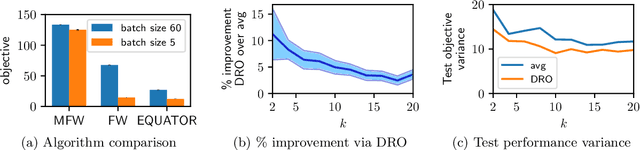
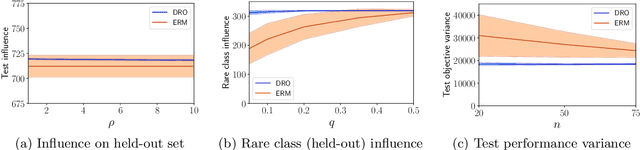
Submodular functions have applications throughout machine learning, but in many settings, we do not have direct access to the underlying function $f$. We focus on stochastic functions that are given as an expectation of functions over a distribution $P$. In practice, we often have only a limited set of samples $f_i$ from $P$. The standard approach indirectly optimizes $f$ by maximizing the sum of $f_i$. However, this ignores generalization to the true (unknown) distribution. In this paper, we achieve better performance on the actual underlying function $f$ by directly optimizing a combination of bias and variance. Algorithmically, we accomplish this by showing how to carry out distributionally robust optimization (DRO) for submodular functions, providing efficient algorithms backed by theoretical guarantees which leverage several novel contributions to the general theory of DRO. We also show compelling empirical evidence that DRO improves generalization to the unknown stochastic submodular function.