Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally-Constrained Policy Optimization via Unbalanced Optimal Transport
Paper and Code
Feb 15, 2021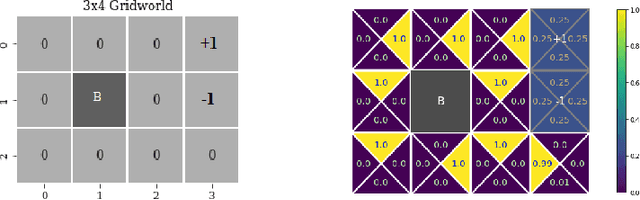
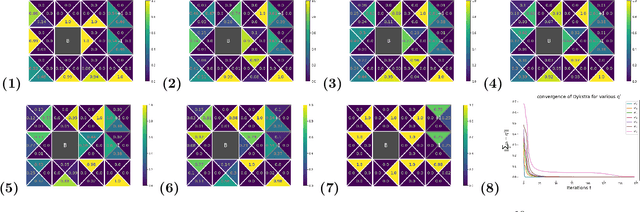

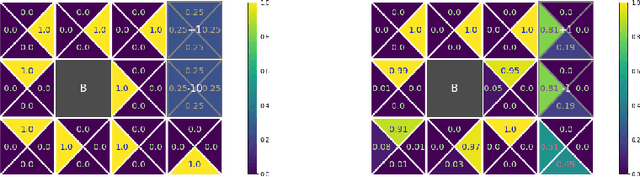
We consider constrained policy optimization in Reinforcement Learning, where the constraints are in form of marginals on state visitations and global action executions. Given these distributions, we formulate policy optimization as unbalanced optimal transport over the space of occupancy measures. We propose a general purpose RL objective based on Bregman divergence and optimize it using Dykstra's algorithm. The approach admits an actor-critic algorithm for when the state or action space is large, and only samples from the marginals are available. We discuss applications of our approach and provide demonstrations to show the effectiveness of our algorithm.
View paper on