 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Newton-Type Methods with Communication Compression and Bernoulli Aggregation
Paper and Code
Jun 07, 2022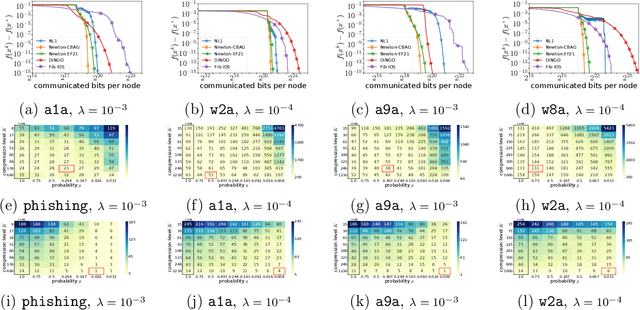

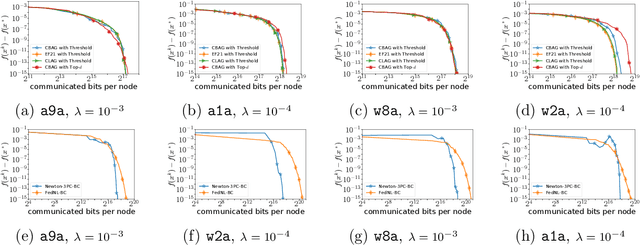
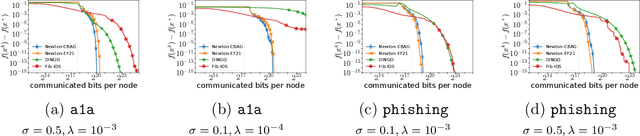
Despite their high computation and communication costs, Newton-type methods remain an appealing option for distributed training due to their robustness against ill-conditioned convex problems. In this work, we study ommunication compression and aggregation mechanisms for curvature information in order to reduce these costs while preserving theoretically superior local convergence guarantees. We prove that the recently developed class of three point compressors (3PC) of Richtarik et al. [2022] for gradient communication can be generalized to Hessian communication as well. This result opens up a wide variety of communication strategies, such as contractive compression} and lazy aggregation, available to our disposal to compress prohibitively costly curvature information. Moreover, we discovered several new 3PC mechanisms, such as adaptive thresholding and Bernoulli aggregation, which require reduced communication and occasional Hessian computations. Furthermore, we extend and analyze our approach to bidirectional communication compression and partial device participation setups to cater to the practical considerations of applications in federated learning. For all our methods, we derive fast condition-number-independent local linear and/or superlinear convergence rates. Finally, with extensive numerical evaluations on convex optimization problems, we illustrate that our designed schemes achieve state-of-the-art communication complexity compared to several key baselines using second-order information.