 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Multi-Task Relationship Learning
Paper and Code
Jun 20, 2017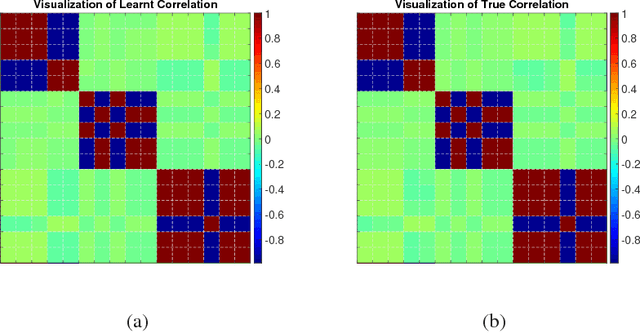
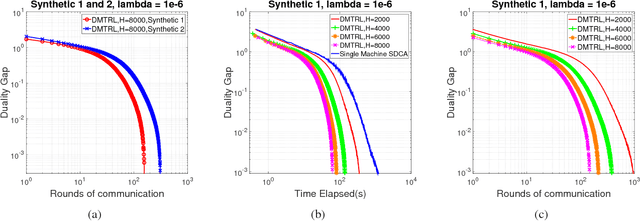

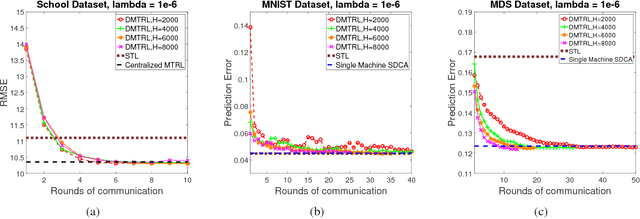
Multi-task learning aims to learn multiple tasks jointly by exploiting their relatedness to improve the generalization performance for each task. Traditionally, to perform multi-task learning, one needs to centralize data from all the tasks to a single machine. However, in many real-world applications, data of different tasks may be geo-distributed over different local machines. Due to heavy communication caused by transmitting the data and the issue of data privacy and security, it is impossible to send data of different task to a master machine to perform multi-task learning. Therefore, in this paper, we propose a distributed multi-task learning framework that simultaneously learns predictive models for each task as well as task relationships between tasks alternatingly in the parameter server paradigm. In our framework, we first offer a general dual form for a family of regularized multi-task relationship learning methods. Subsequently, we propose a communication-efficient primal-dual distributed optimization algorithm to solve the dual problem by carefully designing local subproblems to make the dual problem decomposable. Moreover, we provide a theoretical convergence analysis for the proposed algorithm, which is specific for distributed multi-task relationship learning. We conduct extensive experiments on both synthetic and real-world datasets to evaluate our proposed framework in terms of effectiveness and convergence.