 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Data Vending on Blockchain
Paper and Code
Mar 16, 2018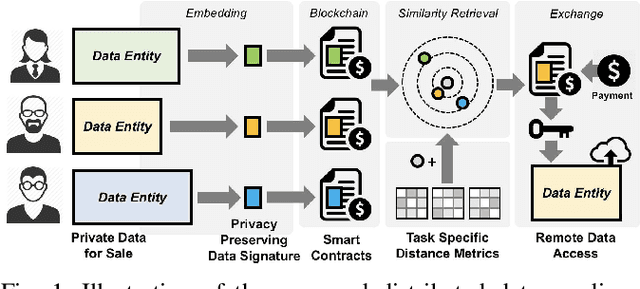
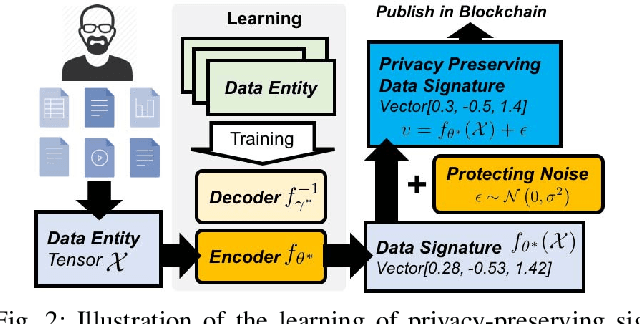
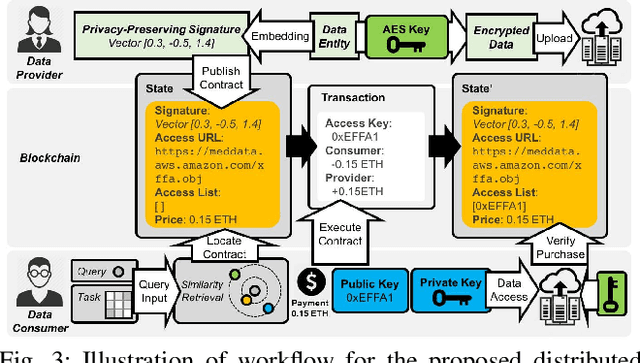
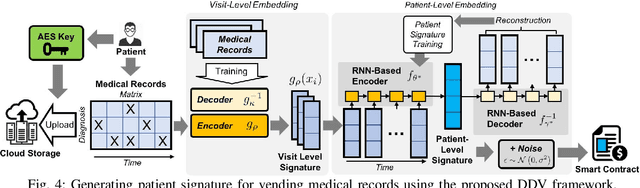
Recent advances in blockchain technologies have provided exciting opportunities for decentralized applications. Specifically, blockchain-based smart contracts enable credible transactions without authorized third parties. The attractive properties of smart contracts facilitate distributed data vending, allowing for proprietary data to be securely exchanged on a blockchain. Distributed data vending can transform domains such as healthcare by encouraging data distribution from owners and enabling large-scale data aggregation. However, one key challenge in distributed data vending is the trade-off dilemma between the effectiveness of data retrieval, and the leakage risk from indexing the data. In this paper, we propose a framework for distributed data vending through a combination of data embedding and similarity learning. We illustrate our framework through a practical scenario of distributing and aggregating electronic medical records on a blockchain. Extensive empirical results demonstrate the effectiveness of our framework.