 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Bandits with Heterogeneous Agents
Paper and Code
Jan 23, 2022
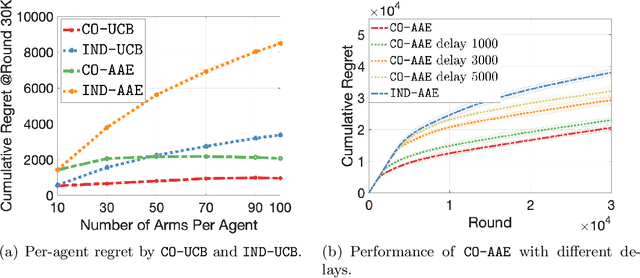
This paper tackles a multi-agent bandit setting where $M$ agents cooperate together to solve the same instance of a $K$-armed stochastic bandit problem. The agents are \textit{heterogeneous}: each agent has limited access to a local subset of arms and the agents are asynchronous with different gaps between decision-making rounds. The goal for each agent is to find its optimal local arm, and agents can cooperate by sharing their observations with others. While cooperation between agents improves the performance of learning, it comes with an additional complexity of communication between agents. For this heterogeneous multi-agent setting, we propose two learning algorithms, \ucbo and \AAE. We prove that both algorithms achieve order-optimal regret, which is $O\left(\sum_{i:\tilde{\Delta}_i>0} \log T/\tilde{\Delta}_i\right)$, where $\tilde{\Delta}_i$ is the minimum suboptimality gap between the reward mean of arm $i$ and any local optimal arm. In addition, a careful selection of the valuable information for cooperation, \AAE achieves a low communication complexity of $O(\log T)$. Last, numerical experiments verify the efficiency of both algorithms.