 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Model Failures as Directions in Latent Space
Paper and Code
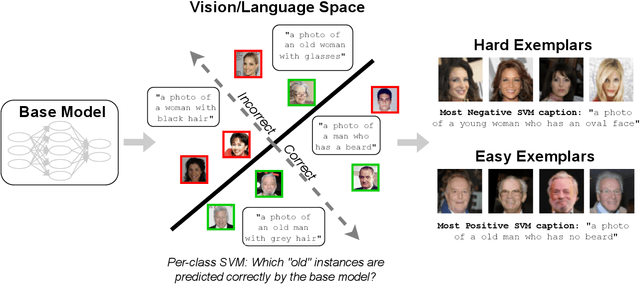

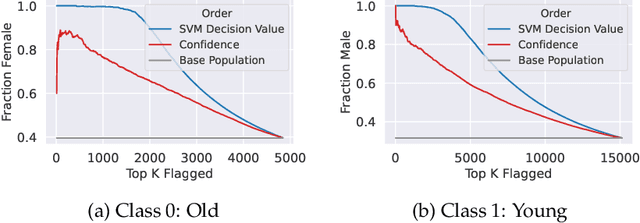

Existing methods for isolating hard subpopulations and spurious correlations in datasets often require human intervention. This can make these methods labor-intensive and dataset-specific. To address these shortcomings, we present a scalable method for automatically distilling a model's failure modes. Specifically, we harness linear classifiers to identify consistent error patterns, and, in turn, induce a natural representation of these failure modes as directions within the feature space. We demonstrate that this framework allows us to discover and automatically caption challenging subpopulations within the training dataset, and intervene to improve the model's performance on these subpopulations. Code available at https://github.com/MadryLab/failure-directions