 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Mathematical Reasoning Capabilities into Small Language Models
Paper and Code
Feb 01, 2024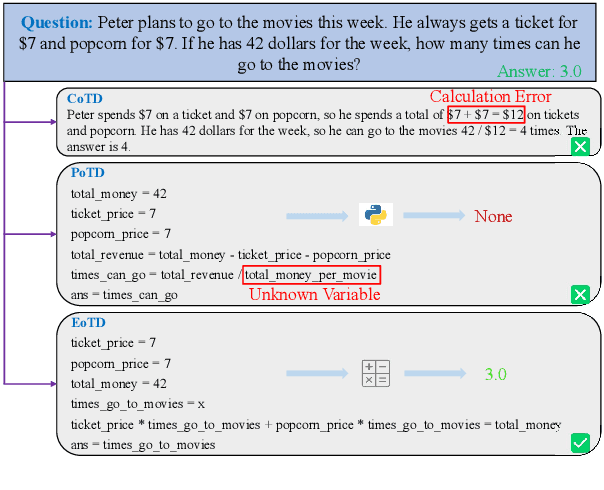
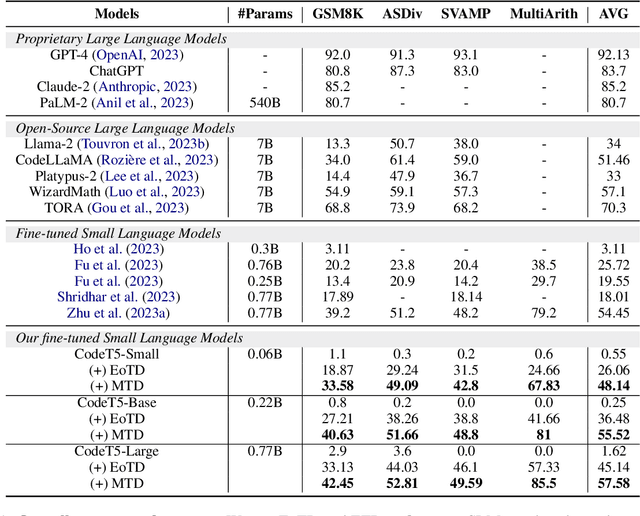
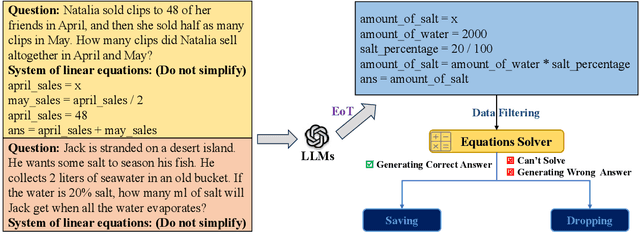
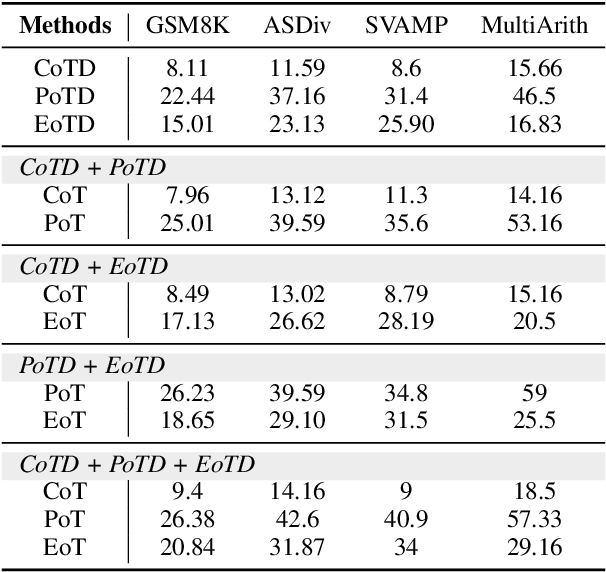
This work addresses the challenge of democratizing advanced Large Language Models (LLMs) by compressing their mathematical reasoning capabilities into sub-billion parameter Small Language Models (SLMs) without compromising performance. We introduce Equation-of-Thought Distillation (EoTD), a novel technique that encapsulates the reasoning process into equation-based representations to construct an EoTD dataset for fine-tuning SLMs. Additionally, we propose the Ensemble Thoughts Distillation (ETD) framework to enhance the reasoning performance of SLMs. This involves creating a reasoning dataset with multiple thought processes, including Chain-of-Thought (CoT), Program-of-Thought (PoT), and Equation-of-Thought (EoT), and using it for fine-tuning. Our experimental findings demonstrate that EoTD significantly boosts the reasoning abilities of SLMs, while ETD enables these models to achieve state-of-the-art reasoning performance.