 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilled Replay: Overcoming Forgetting through Synthetic Samples
Paper and Code
Mar 29, 2021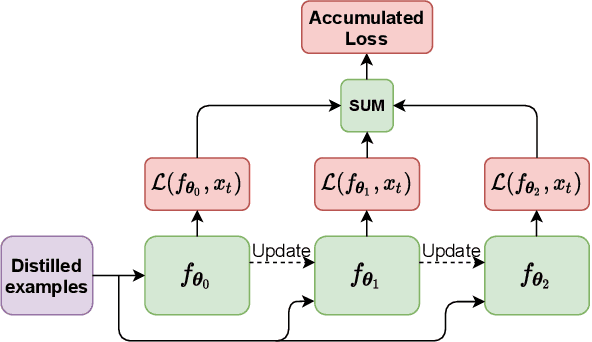

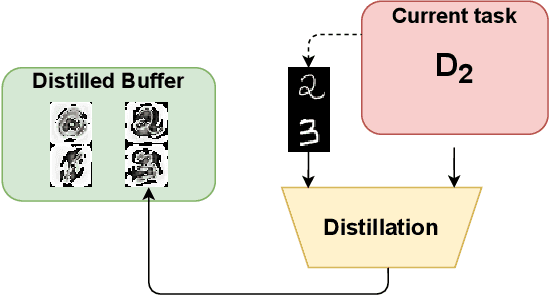
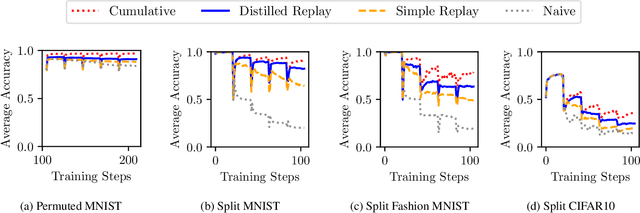
Replay strategies are Continual Learning techniques which mitigate catastrophic forgetting by keeping a buffer of patterns from previous experience, which are interleaved with new data during training. The amount of patterns stored in the buffer is a critical parameter which largely influences the final performance and the memory footprint of the approach. This work introduces Distilled Replay, a novel replay strategy for Continual Learning which is able to mitigate forgetting by keeping a very small buffer (up to $1$ pattern per class) of highly informative samples. Distilled Replay builds the buffer through a distillation process which compresses a large dataset into a tiny set of informative examples. We show the effectiveness of our Distilled Replay against naive replay, which randomly samples patterns from the dataset, on four popular Continual Learning benchmarks.