 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation $\approx$ Early Stopping? Harvesting Dark Knowledge Utilizing Anisotropic Information Retrieval For Overparameterized Neural Network
Paper and Code
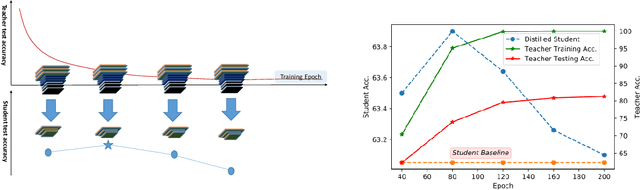
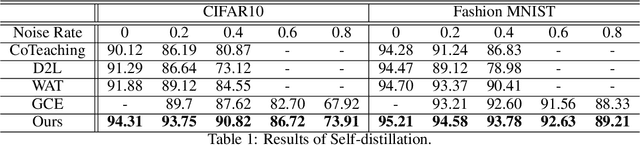
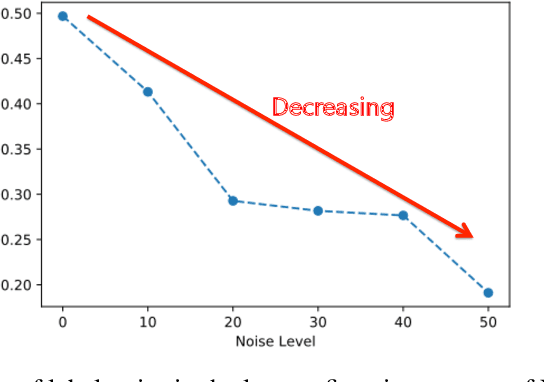
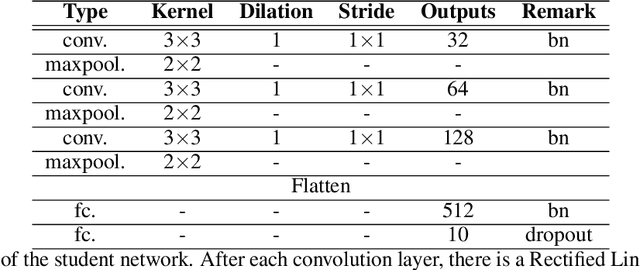
Distillation is a method to transfer knowledge from one model to another and often achieves higher accuracy with the same capacity. In this paper, we aim to provide a theoretical understanding on what mainly helps with the distillation. Our answer is "early stopping". Assuming that the teacher network is overparameterized, we argue that the teacher network is essentially harvesting dark knowledge from the data via early stopping. This can be justified by a new concept, {Anisotropic Information Retrieval (AIR)}, which means that the neural network tends to fit the informative information first and the non-informative information (including noise) later. Motivated by the recent development on theoretically analyzing overparameterized neural networks, we can characterize AIR by the eigenspace of the Neural Tangent Kernel(NTK). AIR facilities a new understanding of distillation. With that, we further utilize distillation to refine noisy labels. We propose a self-distillation algorithm to sequentially distill knowledge from the network in the previous training epoch to avoid memorizing the wrong labels. We also demonstrate, both theoretically and empirically, that self-distillation can benefit from more than just early stopping. Theoretically, we prove convergence of the proposed algorithm to the ground truth labels for randomly initialized overparameterized neural networks in terms of $\ell_2$ distance, while the previous result was on convergence in $0$-$1$ loss. The theoretical result ensures the learned neural network enjoy a margin on the training data which leads to better generalization. Empirically, we achieve better testing accuracy and entirely avoid early stopping which makes the algorithm more user-friendly.