 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisparities in Social Determinants among Performances of Mortality Prediction with Machine Learning for Sepsis Patients
Paper and Code
Dec 15, 2021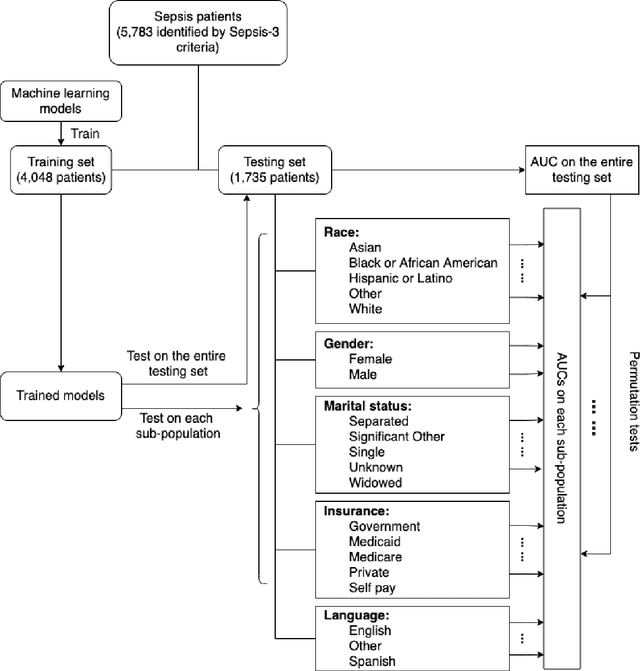
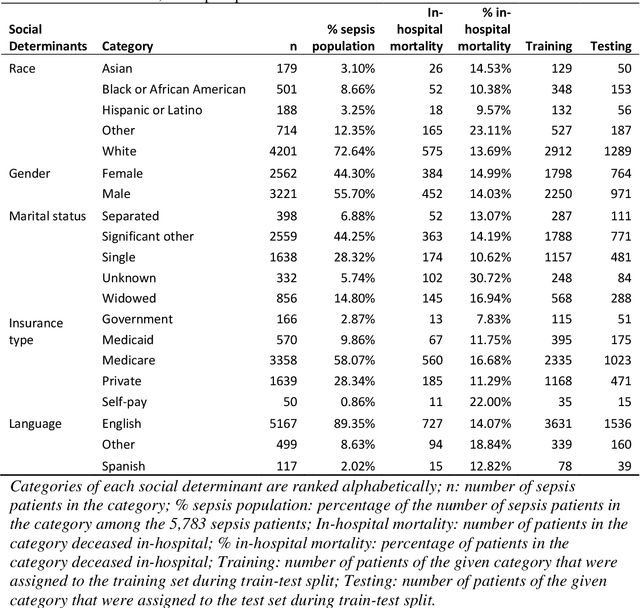
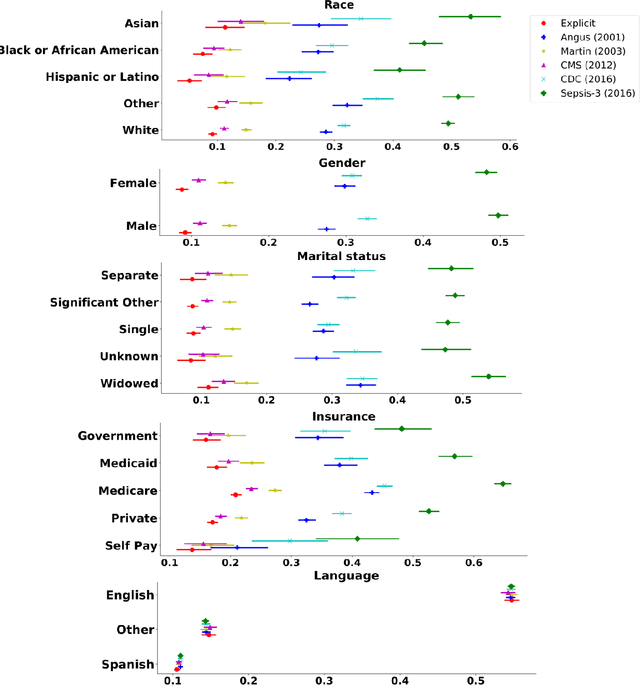
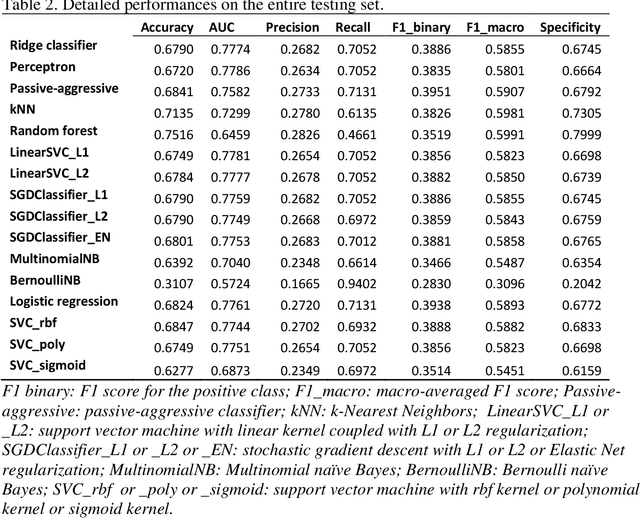
Background Sepsis is one of the most life-threatening circumstances for critically ill patients in the US, while a standardized criteria for sepsis identification is still under development. Disparities in social determinants of sepsis patients can interfere with the risk prediction performances using machine learning. Methods Disparities in social determinants, including race, gender, marital status, insurance types and languages, among patients identified by six available sepsis criteria were revealed by forest plots. Sixteen machine learning classifiers were trained to predict in-hospital mortality for sepsis patients. The performance of the trained model was tested on the entire randomly conducted test set and each sub-population built based on each of the following social determinants: race, gender, marital status, insurance type, and language. Results We analyzed a total of 11,791 critical care patients from the MIMIC-III database. Within the population identified by each sepsis identification method, significant differences were observed among sub-populations regarding race, marital status, insurance type, and language. On the 5,783 sepsis patients identified by the Sepsis-3 criteria statistically significant performance decreases for mortality prediction were observed when applying the trained machine learning model on Asian and Hispanic patients. With pairwise comparison, we detected performance discrepancies in mortality prediction between Asian and White patients, Asians and patients of other races, as well as English-speaking and Spanish-speaking patients. Conclusions Disparities in proportions of patients identified by various sepsis criteria were detected among the different social determinant groups. To achieve accurate diagnosis, a versatile diagnostic system for sepsis is needed to overcome the social determinant disparities of patients.