 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisparate Vulnerability: on the Unfairness of Privacy Attacks Against Machine Learning
Paper and Code
Jun 02, 2019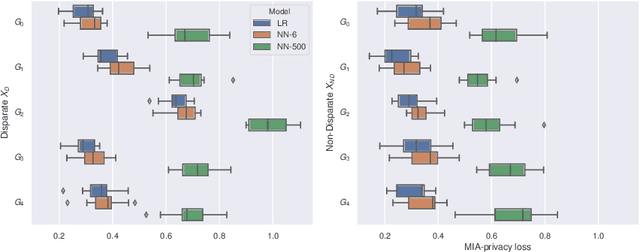
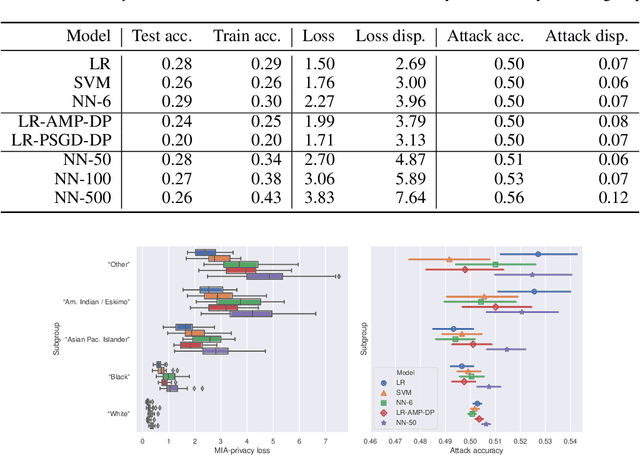
A membership inference attack (MIA) against a machine learning model enables an attacker to determine whether a given data record was part of the model's training dataset or not. Such attacks have been shown to be practical both in centralized and federated settings, and pose a threat in many privacy-sensitive domains such as medicine or law enforcement. In the literature, the effectiveness of these attacks is invariably reported using metrics computed across the whole population. In this paper, we take a closer look at the attack's performance across different subgroups present in the data distributions. We introduce a framework that enables us to efficiently analyze the vulnerability of machine learning models to MIA. We discover that even if the accuracy of MIA looks no better than random guessing over the whole population, subgroups are subject to disparate vulnerability, i.e., certain subgroups can be significantly more vulnerable than others. We provide a theoretical definition for MIA vulnerability which we validate empirically both on synthetic and real data.