 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisinformation Detection: An Evolving Challenge in the Age of LLMs
Paper and Code
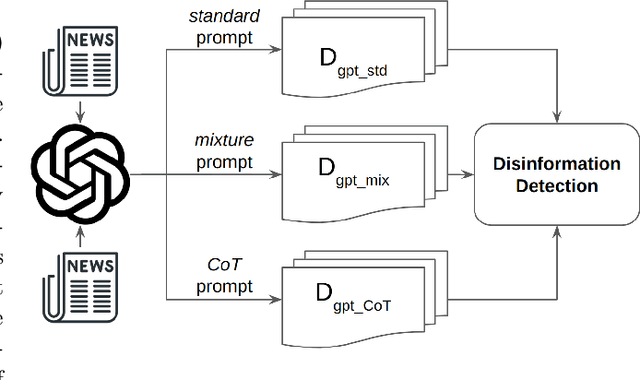
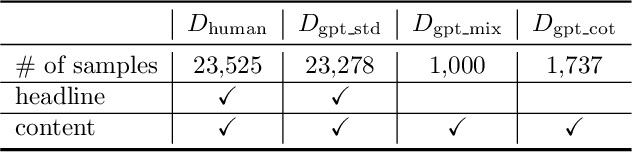
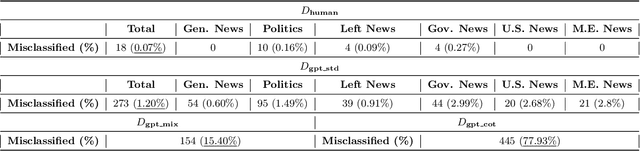

The advent of generative Large Language Models (LLMs) such as ChatGPT has catalyzed transformative advancements across multiple domains. However, alongside these advancements, they have also introduced potential threats. One critical concern is the misuse of LLMs by disinformation spreaders, leveraging these models to generate highly persuasive yet misleading content that challenges the disinformation detection system. This work aims to address this issue by answering three research questions: (1) To what extent can the current disinformation detection technique reliably detect LLM-generated disinformation? (2) If traditional techniques prove less effective, can LLMs themself be exploited to serve as a robust defense against advanced disinformation? and, (3) Should both these strategies falter, what novel approaches can be proposed to counter this burgeoning threat effectively? A holistic exploration for the formation and detection of disinformation is conducted to foster this line of research.