 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling feature and lazy learning in deep neural networks: an empirical study
Paper and Code
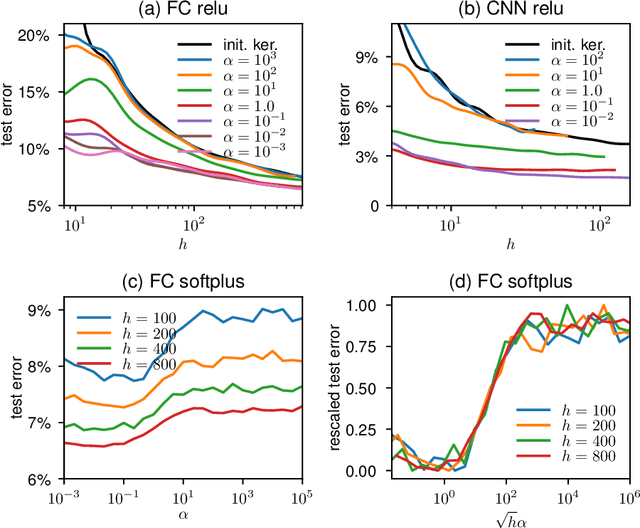

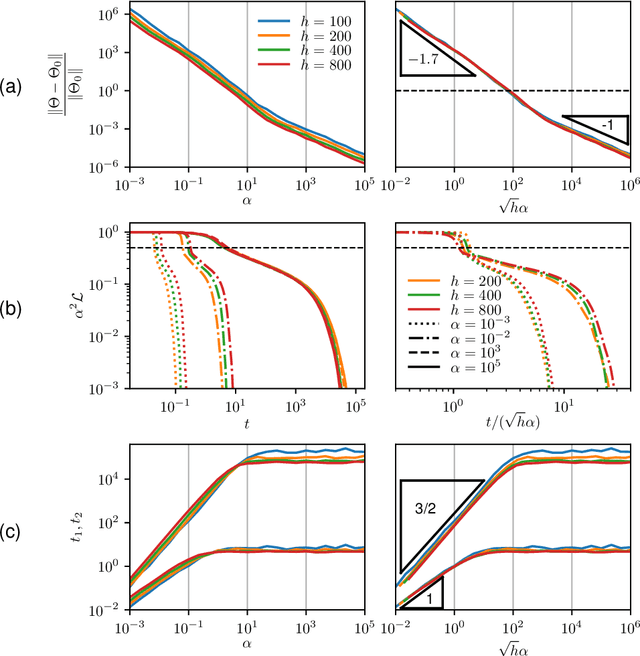
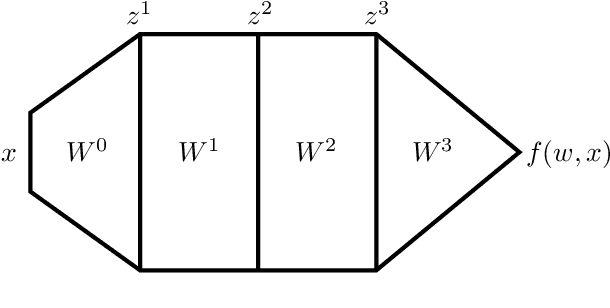
Two distinct limits for deep learning as the net width $h\to\infty$ have been proposed, depending on how the weights of the last layer scale with $h$. In the "lazy-learning" regime, the dynamics becomes linear in the weights and is described by a Neural Tangent Kernel $\Theta$. By contrast, in the "feature-learning" regime, the dynamics can be expressed in terms of the density distribution of the weights. Understanding which regime describes accurately practical architectures and which one leads to better performance remains a challenge. We answer these questions and produce new characterizations of these regimes for the MNIST data set, by considering deep nets $f$ whose last layer of weights scales as $\frac{\alpha}{\sqrt{h}}$ at initialization, where $\alpha$ is a parameter we vary. We performed systematic experiments on two setups (A) fully-connected Softplus momentum full batch and (B) convolutional ReLU momentum stochastic. We find that (1) $\alpha^*=\frac{1}{\sqrt{h}}$ separates the two regimes. (2) for (A) and (B) feature learning outperforms lazy learning, a difference in performance that decreases with $h$ and becomes hardly detectable asymptotically for (A) but is very significant for (B). (3) In both regimes, the fluctuations $\delta f$ induced by initial conditions on the learned function follow $\delta f\sim1/\sqrt{h}$, leading to a performance that increases with $h$. This improvement can be instead obtained at intermediate $h$ values by ensemble averaging different networks. (4) In the feature regime there exists a time scale $t_1\sim\alpha\sqrt{h}$, such that for $t\ll t_1$ the dynamics is linear. At $t\sim t_1$, the output has grown by a magnitude $\sqrt{h}$ and the changes of the tangent kernel $\|\Delta\Theta\|$ become significant. Ultimately, it follows $\|\Delta\Theta\|\sim(\sqrt{h}\alpha)^{-a}$ for ReLU and Softplus activation, with $a<2$ & $a\to2$ when depth grows.