 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminator-Guided Cooperative Diffusion for Joint Audio and Video Generation
Paper and Code
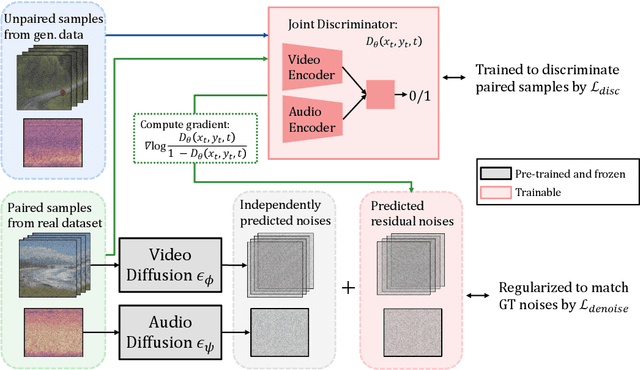
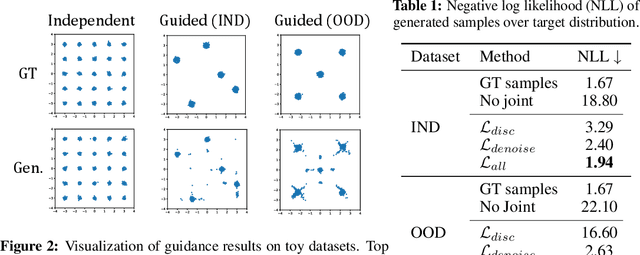


In this study, we aim to construct an audio-video generative model with minimal computational cost by leveraging pre-trained single-modal generative models for audio and video. To achieve this, we propose a novel method that guides each single-modal model to cooperatively generate well-aligned samples across modalities. Specifically, given two pre-trained base diffusion models, we train a lightweight joint guidance module to adjust scores separately estimated by the base models to match the score of joint distribution over audio and video. We theoretically show that this guidance can be computed through the gradient of the optimal discriminator distinguishing real audio-video pairs from fake ones independently generated by the base models. On the basis of this analysis, we construct the joint guidance module by training this discriminator. Additionally, we adopt a loss function to make the gradient of the discriminator work as a noise estimator, as in standard diffusion models, stabilizing the gradient of the discriminator. Empirical evaluations on several benchmark datasets demonstrate that our method improves both single-modal fidelity and multi-modal alignment with a relatively small number of parameters.