 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Langevin Sampler via Wasserstein Gradient Flow
Paper and Code
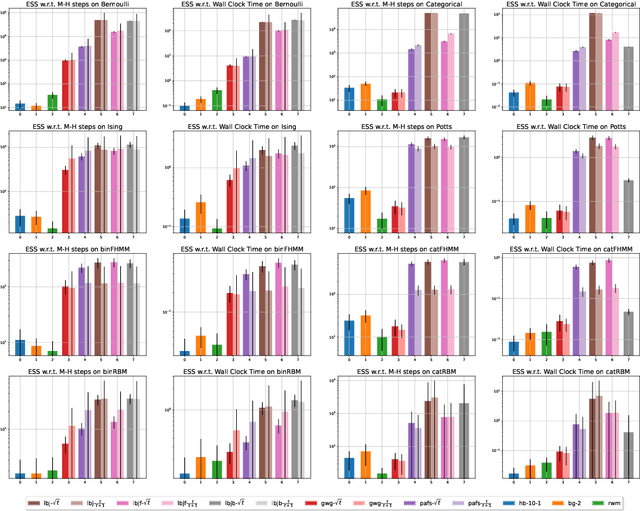


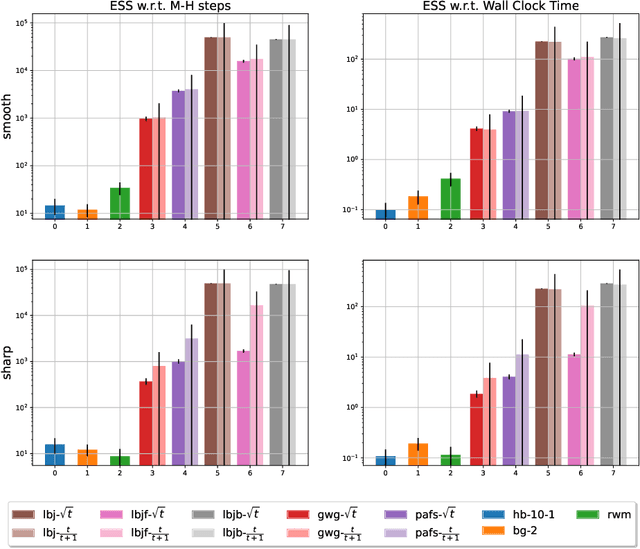
Recently, a family of locally balanced (LB) samplers has demonstrated excellent performance at sampling and learning energy-based models (EBMs) in discrete spaces. However, the theoretical understanding of this success is limited. In this work, we show how LB functions give rise to LB dynamics corresponding to Wasserstein gradient flow in a discrete space. From first principles, previous LB samplers can then be seen as discretizations of the LB dynamics with respect to Hamming distance. Based on this observation, we propose a new algorithm, the Locally Balanced Jump (LBJ), by discretizing the LB dynamics with respect to simulation time. As a result, LBJ has a location-dependent "velocity" that allows it to make proposals with larger distances. Additionally, LBJ decouples each dimension into independent sub-processes, enabling convenient parallel implementation. We demonstrate the advantages of LBJ for sampling and learning in various binary and categorical distributions.