 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Reliable Correlations in Categorical Data
Paper and Code

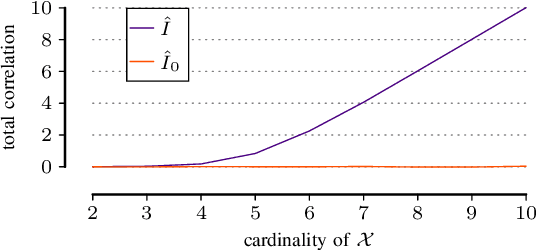
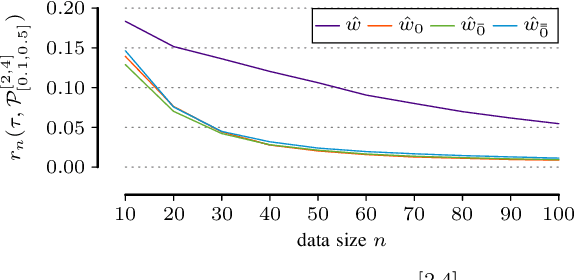

In many scientific tasks we are interested in discovering whether there exist any correlations in our data. This raises many questions, such as how to reliably and interpretably measure correlation between a multivariate set of attributes, how to do so without having to make assumptions on distribution of the data or the type of correlation, and, how to efficiently discover the top-most reliably correlated attribute sets from data. In this paper we answer these questions for discovery tasks in categorical data. In particular, we propose a corrected-for-chance, consistent, and efficient estimator for normalized total correlation, by which we obtain a reliable, naturally interpretable, non-parametric measure for correlation over multivariate sets. For the discovery of the top-k correlated sets, we derive an effective algorithmic framework based on a tight bounding function. This framework offers exact, approximate, and heuristic search. Empirical evaluation shows that already for small sample sizes the estimator leads to low-regret optimization outcomes, while the algorithms are shown to be highly effective for both large and high-dimensional data. Through two case studies we confirm that our discovery framework identifies interesting and meaningful correlations.