 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering maximally consistent distribution of causal tournaments with Large Language Models
Paper and Code
Dec 18, 2024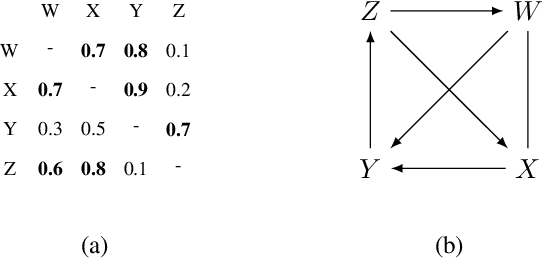
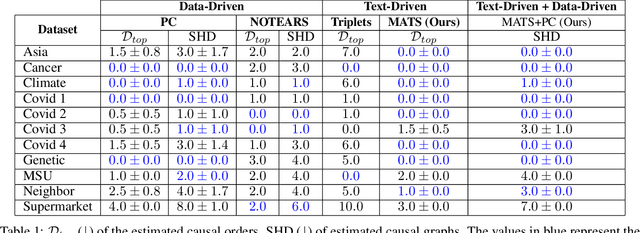
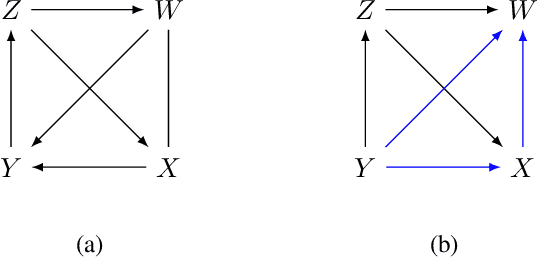
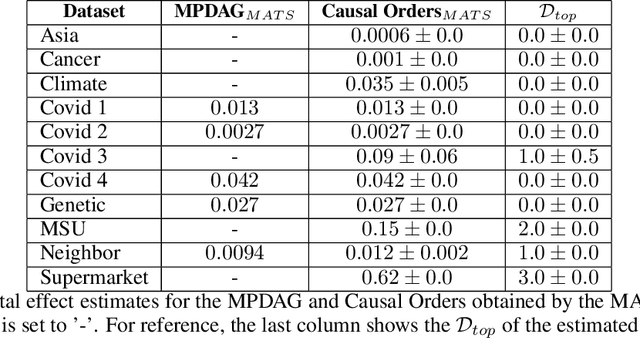
Causal discovery is essential for understanding complex systems, yet traditional methods often depend on strong, untestable assumptions, making the process challenging. Large Language Models (LLMs) present a promising alternative for extracting causal insights from text-based metadata, which consolidates domain expertise. However, LLMs are prone to unreliability and hallucinations, necessitating strategies that account for their limitations. One such strategy involves leveraging a consistency measure to evaluate reliability. Additionally, most text metadata does not clearly distinguish direct causal relationships from indirect ones, further complicating the inference of causal graphs. As a result, focusing on causal orderings, rather than causal graphs, emerges as a more practical and robust approach. We propose a novel method to derive a distribution of acyclic tournaments (representing plausible causal orders) that maximizes a consistency score. Our approach begins by computing pairwise consistency scores between variables, yielding a cyclic tournament that aggregates these scores. From this structure, we identify optimal acyclic tournaments compatible with the original tournament, prioritizing those that maximize consistency across all configurations. We tested our method on both classical and well-established bechmarks, as well as real-world datasets from epidemiology and public health. Our results demonstrate the effectiveness of our approach in recovering distributions causal orders with minimal error.