 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscount Factor as a Regularizer in Reinforcement Learning
Paper and Code
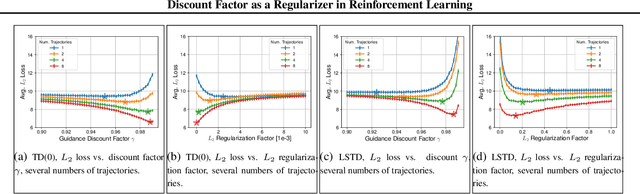

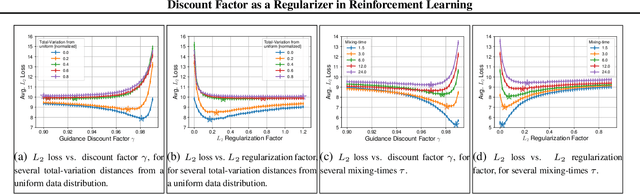
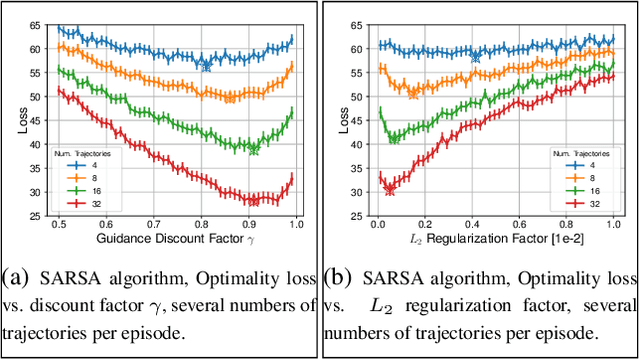
Specifying a Reinforcement Learning (RL) task involves choosing a suitable planning horizon, which is typically modeled by a discount factor. It is known that applying RL algorithms with a lower discount factor can act as a regularizer, improving performance in the limited data regime. Yet the exact nature of this regularizer has not been investigated. In this work, we fill in this gap. For several Temporal-Difference (TD) learning methods, we show an explicit equivalence between using a reduced discount factor and adding an explicit regularization term to the algorithm's loss. Motivated by the equivalence, we empirically study this technique compared to standard $L_2$ regularization by extensive experiments in discrete and continuous domains, using tabular and functional representations. Our experiments suggest the regularization effectiveness is strongly related to properties of the available data, such as size, distribution, and mixing rate.