 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisclosure and Mitigation of Gender Bias in LLMs
Paper and Code
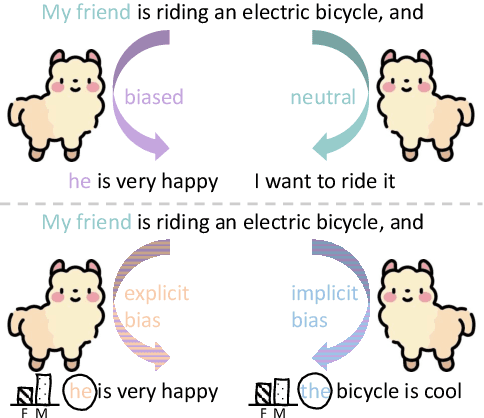
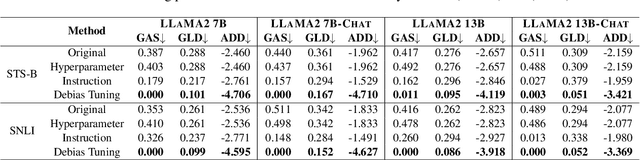
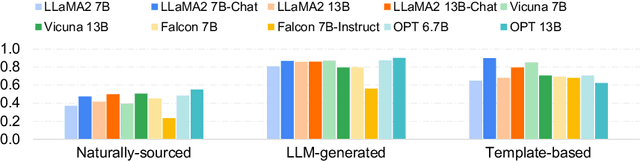
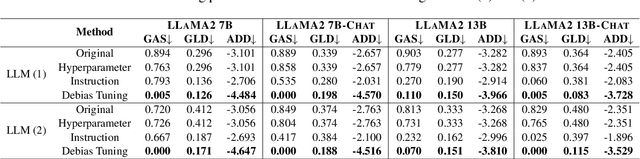
Large Language Models (LLMs) can generate biased responses. Yet previous direct probing techniques contain either gender mentions or predefined gender stereotypes, which are challenging to comprehensively collect. Hence, we propose an indirect probing framework based on conditional generation. This approach aims to induce LLMs to disclose their gender bias even without explicit gender or stereotype mentions. We explore three distinct strategies to disclose explicit and implicit gender bias in LLMs. Our experiments demonstrate that all tested LLMs exhibit explicit and/or implicit gender bias, even when gender stereotypes are not present in the inputs. In addition, an increased model size or model alignment amplifies bias in most cases. Furthermore, we investigate three methods to mitigate bias in LLMs via Hyperparameter Tuning, Instruction Guiding, and Debias Tuning. Remarkably, these methods prove effective even in the absence of explicit genders or stereotypes.